Hexagonale Architektur in der Praxis: Umsetzung in einem Java/Spring Boot Projekt – Teil 5: Anbindung der Datenbank (am Beispiel einer MongoDB)
Nachdem wir im Laufe dieser Serie eine voll funktionsfähige To-Do-Listen-Anwendung entwickelt haben (den kompletten Code findet ihr auf GitHub), wollen wir uns zum Abschluss noch anschauen, wie die gewählte Architektur es uns ermöglicht, ganz ohne Änderungen am Applikationskern und mit minimalem Aufwand unseren In-Memory Cache durch eine persistente MongoDB zu ersetzen.
Im ersten Teil dieser Serie haben wir ein frisches Java/Spring-Boot-Projekt aufgesetzt und konfiguriert. Wir haben uns überlegt, wie wir uns die Architektur der Anwendung und ihre Umsetzung vorstellen und diese Vorstellung mittels ArchUnit in einem automatisierten Architekturtest festgehalten.
Im zweiten Teil sind wir mit der Modellierung der Domäne, der Implementierung der Kernlogik und der Datenhaltung der Anwendung in die eigentliche Entwicklung gestartet.
Im dritten Teil haben wir alle grundlegenden Funktionalitäten unserer Anwendung implementiert, sodass diese nutzbar wurde.
Im vierten Teil haben wir uns angesehen, welche Auswirkungen eine Anpassung am Domänenmodell auf die bestehende Anwendung hat. Außerdem wurde die Applikationsschicht mit einer geplanten Aufgabe zum regelmäßigen Senden von Benachrichtigungen gefüllt sowie mit der Möglichkeit, beim Anwendungsstart automatisch einige Beispieltasks zu erzeugen.
Nun geht es also noch darum, den In-Memory-Cache abzulösen durch eine persistente MongoDB – was dank unserer Architektur mit minimalem Aufwand möglich wird.
Setup der MongoDB
Solltet ihr bereits eine MongoDB-Instanz zur Verfügung haben, könnt ihr diesen Schritt natürlich überspringen. Ansonsten stellt folgende Docker Compose Datei eine minimal lauffähige Konfiguration bereit, die für unsere Zwecke völlig ausreicht:
# See https://hub.docker.com/_/mongo
services:
mongo:
image: "mongo:6.0.7"
restart: "unless-stopped"
ports:
- "27017:27017" # Map the port to make it accessible outside the container
environment:
MONGO_INITDB_ROOT_USERNAME: "root"
MONGO_INITDB_ROOT_PASSWORD: "example" # Use secrets in a production application instead of plaintext passwords!Ihr benötigt hierzu Docker mit installiertem Compose-Plugin und könnt die Datenbankinstanz dann mit dem Befehl
docker-compose -f mongodb-compose.yaml upaufsetzen. Die Instanz ist dann auf Port 27017 mit den
Zugangsdaten root / example ansprechbar. Diese
Konfiguration könnt ihr natürlich nach Belieben in der obigen Compose
Datei anpassen.
Nachdem wir nun eine Datenbank zur Verfügung haben, wollen wir unsere Anwendung im nächsten Schritt mit dieser verbinden.
Anbindung der Anwendung an die Datenbank
In einem ersten Schritt hinterlegen wir dazu die Verbindungsdaten in den application.properties:
# MongoDB config
spring.data.mongodb.host=localhost
spring.data.mongodb.port=27017
spring.data.mongodb.authentication-database=admin
spring.data.mongodb.database=test
spring.data.mongodb.username=root
spring.data.mongodb.password=exampleIn einer produktiven Anwendung sollte das Passwort natürlich in einem Secret Manager hinterlegt werden, diesen Umweg sparen wir uns aber an dieser Stelle.
Als Nächstes fügen wir die Abhängigkeit spring-boot-starter-data-mongodb zu unserem Projekt in der pom.xml hinzu:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>Diese kann, ohne weitere Zuarbeit unsererseits, mithilfe der eben hinterlegten Optionen nun eine Verbindung zur Datenbank herstellen.
Schließlich fehlt uns noch eine Möglichkeit zu entscheiden, ob wir wie bisher mit einem Cache oder mit der neuen Datenbank arbeiten möchten. Dazu führen wir zuerst einen weiteren Konfigurationsparameter
# Use 'cache' or 'database'
storage.type=cacheein und müssen zum Abschluss noch – basierend auf dem gesetzten Wert dieses Parameters – unsere Anwendung entweder mit dem schon existierenden Cache-Adapter oder mit einem hypothetischen Datenbank-Adapter laden.
Bedingtes Laden von Komponenten
Um dies zu ermöglichen, werden wir nun Teile unserer Anwendung nur
noch bedingt beim Anwendungsstart laden. Hierzu führen wir mehrere
Anpassungen an unserer Einstiegsklasse
HexagonalToDoListApplication durch.
Zuerst einmal schließen wir sowohl den Cache-Adapter, als auch den noch zu implementierenden Datenbank-Adapter, komplett vom Anwendungsstart aus. Dazu hinterlegen wir folgende @ComponentScan-Konfiguration an der Klasse:
@ComponentScan(
excludeFilters = {
@ComponentScan.Filter(type = FilterType.REGEX, pattern = ADAPTER_PACKAGE + ".cache.*"),
@ComponentScan.Filter(type = FilterType.REGEX, pattern = ADAPTER_PACKAGE + ".mongodb.*"),
}
)Hierbei verwenden wir die Konstante
String ADAPTER_PACKAGE = "de.colenet.hexagonal.todo.list.adapter".
Um unsere Anwendung wie bisher mit einem Cache starten zu können, legen wir eine neue, innere, mit @Configuration-annotierte Klasse an, die einerseits den eben ausgeschlossenen Cache-Adapter wieder lädt, falls storage.type="cache" gesetzt ist, und andererseits noch die AutoConfiguration der eben hinzugefügten Abhängigkeit unterdrückt. Letzteres schließen wir an dieser Stelle statt in der Einstiegsklasse aus, da ansonsten (aufgrund der Art und Weise, wie AutoConfiguration in Spring funktioniert) erheblich mehr Konfigurationsarbeit von uns zu leisten wäre. Die entstandene Konfiguration sieht folgendermaßen aus:
@Configuration
@ComponentScan(ADAPTER_PACKAGE + ".cache")
@ConditionalOnProperty(name = "storage.type", havingValue = "cache")
@EnableAutoConfiguration(
exclude = {
MongoAutoConfiguration.class, MongoDataAutoConfiguration.class, MongoRepositoriesAutoConfiguration.class,
}
)
class CacheConfiguration {}Für die Datenbank gehen wir analog vor, nur dass wir hier keine Anpassung an der AutoConfiguration benötigen:
@Configuration
@ComponentScan(ADAPTER_PACKAGE + ".mongodb")
@ConditionalOnProperty(name = "storage.type", havingValue = "database")
class DatabaseConfiguration {}Starten wir nun unsere Anwendung mit der Konfiguration
storage.type="cache", so verhält sich alles wie bisher.
Versuchen wir hingegen mit storage.type="database" zu
starten, wird dies derzeit noch nicht funktionieren, da keine
Implementierung für TaskRepository unter den geladenen
Komponenten zu finden ist. Das beheben wir natürlich, in dem wir im
Folgenden abschließend unseren Datenbank-Adapter implementieren.
Bemerkenswert ist an dieser Stelle, dass wir hiermit bereits jegliche Konfigurationsarbeit geleistet haben und auch keinerlei weitere Änderungen in unserem Bestandscode notwendig sind; wir werden im Folgenden (abgesehen von Tests) ausschließlich in einem neuen Adapter arbeiten. Dieser Umstand demonstriert deutlich einen der großen Vorteile der hexagonalen Architektur: Infrastrukturänderungen haben nur sehr lokale Auswirkungen. Wir mussten nicht eine einzige Zeile Code in unserem Applikationskern oder in anderen Adaptern anpassen!
Kommen wir nun also endlich zum letzten Puzzleteil: Dem Datenbank-Adapter.
Implementation des Datenbank-Adapters
Hier passiert überhaupt nichts Neues mehr. Wir haben in den vorherigen Adaptern alle Techniken kennengelernt und gehen hier völlig analog vor.
Zuerst legen wir uns eine geeignete Darstellung unseres Datenmodells für den gegebenen Zweck zurecht. Wie im REST-Adapter auch, greifen wir hier auf eine Darstellung als reinen Produkttyp zurück, sind aber in unseren Zeittypen konkreter als dort, da diese hier entsprechend unterstützt werden:
public record TaskEntity(
String id,
String description,
LocalDate dueDate,
boolean completed,
LocalDateTime completionTime
) {}Natürlich brauchen wir an dieser Stelle dann auch wieder einen geeigneten Mapper, um zwischen dieser Darstellung und unserem Domänenmodell hin- und herwechseln zu können:
@Component
public class MongoMapper {
public TaskEntity toEntity(Task model) {
return new TaskEntity(
model.id().toString(),
model.description(),
model.dueDate().orElse(null),
switch (model) {
case OpenTask __ -> false;
case CompletedTask __ -> true;
},
switch (model) {
case OpenTask __ -> null;
case CompletedTask t -> t.completionTime();
}
);
}
public Task toModel(TaskEntity entity) {
return entity.completed() ? toCompletedTask(entity) : toOpenTask(entity);
}
private static CompletedTask toCompletedTask(TaskEntity entity) {
return new CompletedTask(
UUID.fromString(entity.id()),
entity.description(),
Optional.ofNullable(entity.dueDate()),
entity.completionTime()
);
}
private static OpenTask toOpenTask(TaskEntity entity) {
return new OpenTask(UUID.fromString(entity.id()), entity.description(), Optional.ofNullable(entity.dueDate()));
}
}Wir haben nun also drei verschiedene Ausprägungen eines
Tasks. Einerseits unser rein durch die Fachlichkeit motiviertes
Domänenmodell Task, andererseits zwei zweckgebundene, durch
die gewählte Infrastruktur beeinflusste, Ausprägungen
TaskDto und TaskEntity. Diese können wir nach
Bedarf völlig unabhängig voneinander evolvieren (durch geeignete
Anpassung an den entsprechenden Mappern) und sind so etwa
gerade dazu in der Lage, unsere Persistenzinfrastruktur grundlegend zu
verändern, ohne die öffentliche API der Anwendung zu verändern.
Als letzter Schritt bleibt jetzt also nur die Implementierung von TaskRepository. Hierzu legen wir erst ein Spring Data Repository
@Repository
public interface BaseMongoTaskRepository extends MongoRepository<TaskEntity, String> {
List<TaskEntity> findByDueDateIsBeforeOrDueDateEquals(LocalDate beforeDate, LocalDate equalsDate);
default List<TaskEntity> findByDueDateIsBeforeOrDueDateEquals(LocalDate date) {
return findByDueDateIsBeforeOrDueDateEquals(date, date);
}
}an, welches die eigentliche Arbeit verrichten wird. In unserer Implementierung von TaskRepository werden wir jetzt nur noch Aufrufe dieses Repositories, sowie des zuvor angelegten Mappers, auf geeignete Art und Weise zusammenfügen:
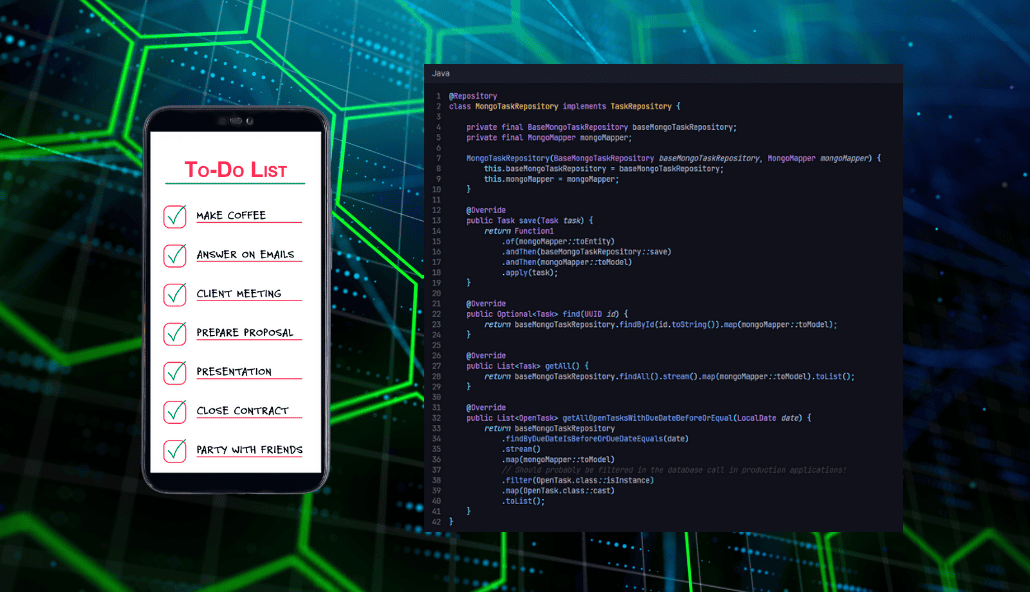
@Repository
class MongoTaskRepository implements TaskRepository {
private final BaseMongoTaskRepository baseMongoTaskRepository;
private final MongoMapper mongoMapper;
MongoTaskRepository(BaseMongoTaskRepository baseMongoTaskRepository, MongoMapper mongoMapper) {
this.baseMongoTaskRepository = baseMongoTaskRepository;
this.mongoMapper = mongoMapper;
}
@Override
public Task save(Task task) {
return Function1
.of(mongoMapper::toEntity)
.andThen(baseMongoTaskRepository::save)
.andThen(mongoMapper::toModel)
.apply(task);
}
@Override
public Optional<Task> find(UUID id) {
return baseMongoTaskRepository.findById(id.toString()).map(mongoMapper::toModel);
}
@Override
public List<Task> getAll() {
return baseMongoTaskRepository.findAll().stream().map(mongoMapper::toModel).toList();
}
@Override
public List<OpenTask> getAllOpenTasksWithDueDateBeforeOrEqual(LocalDate date) {
return baseMongoTaskRepository
.findByDueDateIsBeforeOrDueDateEquals(date)
.stream()
.map(mongoMapper::toModel)
// Should probably be filtered in the database call in production applications!
.filter(OpenTask.class::isInstance)
.map(OpenTask.class::cast)
.toList();
}
}Damit haben wir unsere Implementierung endlich abgeschlossen und
können unsere Anwendung schließlich mit der Konfiguration
storage.type="database" starten und unsere Tasks persistent
in der anfangs angelegten Datenbank speichern.
Randbemerkung: Testing
Um sicherzustellen, dass unser neuer Datenbank-Adapter nichts am Verhalten der Anwendung ändert, habe ich die bereits existierenden Integrations- und End-To-End-Tests so abstrahiert, dass sie sowohl gegen den Cache- als auch gegen den Datenbank-Adapter gefahren werden können. Das liefert uns zumindest eine gewisse Konfidenz, dass sich die beiden Persistenz-Modi in ihrem Verhalten nach außen nicht unterscheiden.
Auch wenn Testing nicht im Fokus dieser Reihe lag, lade ich euch dazu ein, euch die Details hierzu im Repository anzuschauen.
Die Vorteile hexagonaler Architektur nutzen
Hiermit sind wir am Ende unserer Reise angelangt. Zu Beginn des ersten Teils habe ich der hexagonalen Architektur Vorteile wie etwa ein domänenzentriertes Design, Flexibilität und eine klare Projektstruktur zugeschrieben. In diesem Teil konnten wir außerdem sehen, dass das Infrastrukturthema Cache oder Datenbank zur Datenhaltung keine einzige Zeile an Codeänderungen in der Domänenschicht erforderte. Hätten wir unsere Anforderung leicht abgeändert zu Cache durch Datenbank ersetzen, wären noch nicht einmal die Änderungen zum bedingten Laden von Komponenten notwendig gewesen und wir hätten einzig den Cacheadapter durch einen Datenbankadapter ersetzen müssen.
Ihr habt in dieser Reihe einen von vielen möglichen Wegen gesehen, wie sich eine hexagonale Architektur in Java mit Spring umsetzen lässt. Die gelernte Vorgehensweise lässt sich aber natürlich konzeptuell auch auf andere Sprachen und Frameworks – mit entsprechenden technischen Anpassungen – übertragen.
Probiert es in eurem nächsten Projekt doch mal aus! Lasst mich gerne wissen, was eure Erfahrungen dabei sind.
Nutzt die Kommentarfunktion am Ende des Beitrags natürlich gerne auch für eure Fragen und Anmerkungen.
Alle Folgen der Reihe
„Hexagonale Architektur in der Praxis: Umsetzung in einem Java/Spring-Boot-Projekt“
Teil 1: Projektbeschreibung, Setup und automatische Architekturtests
Teil 2: Modellierung, Kernlogik und In-Memory Cache
Teil 3: REST-Schnittstelle mit Antikorruptionsschicht
Teil 4: Folgen einer Änderung am Domänenmodell und die Applikationsschicht
Teil 5: Anbindung der Datenbank (am Beispiel einer MongoDB)
Fragen, Anmerkungen oder Austausch zum Thema gewünscht?
Nutzt gerne die Kommentarfunktion unter dem Beitrag und Ricardo meldet sich bei euch zurück.