Hexagonale Architektur in der Praxis: Umsetzung in einem Java/Spring-Boot-Projekt – Teil 2: Modellierung, Kernlogik und In-Memory Cache
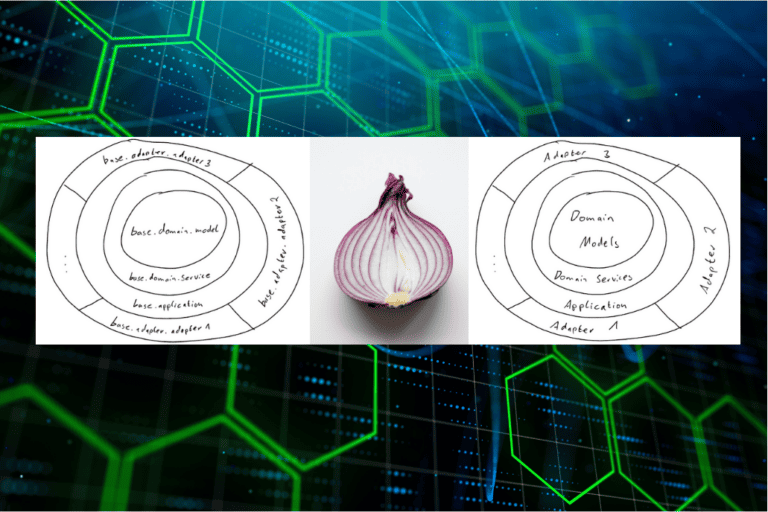
Das Vorhaben: Hexagonale Architektur in der Praxis verstehen
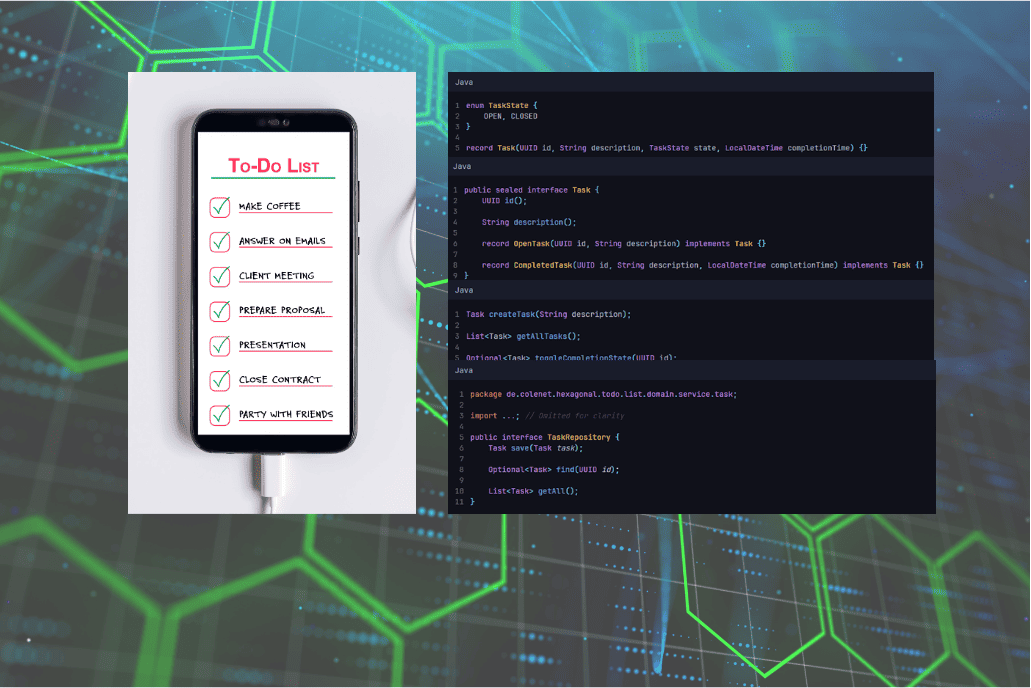
Diese Artikel-Reihe ist der hexagonalen Architektur gewidmet: Wir möchten ihre Grundprinzipien verstehen und dazu in der Praxis erleben. Wir werden uns anschauen, wie sich eine hexagonale Architektur in einer typischen Webanwendung praktisch realisieren lässt. Dazu werden wir Schritt für Schritt eine kleine To-do-Listen-Anwendung entwickeln, die es ermöglichen soll, Tasks anzulegen, angelegte Tasks anzuzeigen und Tasks als erledigt zu markieren. Die Anwendung wird über eine REST-Schnittstelle bedienbar sein und die Tasks werden konfigurierbar entweder In-Memory oder persistent in einer echten MongoDB verwaltet.
Im ersten Teil dieser Serie haben wir ein frisches Java/Spring-Boot-Projekt aufgesetzt und konfiguriert. Wir haben uns überlegt, wie wir uns die Architektur der Anwendung und ihre Umsetzung vorstellen und diese Vorstellung mittels ArchUnit in einem automatisierten Architekturtest festgehalten.
Nun wollen wir mit der tatsächlichen Entwicklung starten und uns in diesem Teil der Serie mit der Modellierung der Domäne, der Kernlogik der Anwendung sowie dem Bereitstellen einer Schnittstelle – um die Anwendung auch wirklich verwenden zu können – befassen.
Den Code findet ihr auch zu diesem Teil zum Nachvollziehen auf GitHub.
Das Domänenmodell
Für unsere To-do-Listen-Anwendung soll es ein einziges Domänenobjekt geben, nämlich einen Task. Dieser soll ganz grundlegende Informationen enthalten: Eine Beschreibung, den Zustand, ob der Task noch offen, oder er bereits erledigt ist und, falls erledigt, den Abschlusszeitpunkt. Außerdem wollen wir den Objekten noch eine ID zuweisen, um sie eindeutig identifizieren zu können (und zum Beispiel zwei offene Tasks mit gleicher Beschreibung voneinander unterscheiden zu können).
Bei der Realisierung dieses Modells im Code wollen wir uns dabei so genau wie möglich an den Domänenanforderungen orientieren. Insbesondere wollen wir uns hier nicht von infrastrukturellen/technischen Gedanken wie Lässt sich das Modellobjekt serialisieren?, Ist das Design geeignet für eine relationale Datenbank? oder Ähnlichen beeinflussen lassen. Für solche Belange werden wir stattdessen später dedizierte, optimierte Datenstrukturen anlegen und im entsprechenden Kontext (lokal!) verwenden. Im Herzen unserer Anwendung wollen wir hingegen so nahe an der Fachdomäne sein wie möglich.
Wir wollen also einerseits die Typen unserer Eigenschaften so spezifisch und aussagekräftig wie möglich wählen – etwa soll unsere ID vom Typ UUID und nicht etwa nur ein String oder int sein – und andererseits wollen wir es unmöglich (bzw. in der Praxis zumindest möglichst schwierig) machen, in der Domäne unmögliche Zustände überhaupt darstellen zu können (und damit Fehler kategorisch ausschließen).
Der zweite Punkt bedeutet für uns an dieser Stelle konkret, dass wir nicht etwa ein einziges Task-Objekt in der Form
enum TaskState {
OPEN, CLOSED
}
record Task(UUID id, String description, TaskState state, LocalDateTime completionTime) {}darstellen möchten, denn sonst würde uns nichts davon abhalten, einen offenen Task mit gesetzter Abschlusszeit anzulegen.
Stattdessen wollen wir strikt zwischen offenen und geschlossenen Tasks unterscheiden und nur geschlossenen Tasks die Eigenschaft completionTime zuordnen. In der Theorie sprechen wir hierbei von einem sogenannten Summentyp, wohingegen die ungewünschte Darstellung oben einen Produkttyp darstellt. Zur Umsetzung können wir dazu das kürzlich mit Java 17 eingeführte sealed Schlüsselwort verwenden:
public sealed interface Task {
UUID id();
String description();
record OpenTask(UUID id, String description) implements Task {}
record CompletedTask(UUID id, String description, LocalDateTime completionTime) implements Task {}
}Dieses Interface legen wir dabei entsprechend unserer Überlegungen im vorangegangen Post im Paket de.colenet.hexagonal.todo.list.domain.model.task ab. Durch das Versiegeln des Interfaces Task stellen wir sicher, dass dieses ausschließlich von den beiden im Rumpf definierten Klassen OpenTask und CompletedTask implementiert werden kann. Dass wir die geteilten Eigenschaften id und description zusätzlich zu den Klasseneigenschaften auch noch im Interface direkt deklarieren, ist strikt optional und hat rein ergonomische Gründe: An vielen Stellen der Anwendung wird es uns nicht interessieren, ob ein konkreter Task noch offen oder schon abgeschlossen ist, und hierdurch ersparen wir uns an diesen Stellen Fallunterscheidungen.
Wollten wir in unserer Modellierung noch genauer sein, so könnten wir uns für unsere description auch noch einen Datentyp NonEmptyString mit entsprechender Absicherung der geforderten nicht-leer Bedingung im Konstruktor anlegen. Der Einfachheit halber sehen wir davon an dieser Stelle aber ab.
Gewappnet mit dieser Darstellung unseres Domänenmodells wollen wir uns nun der Kernfunktionalität unserer Anwendung zuwenden: dem Erzeugen, Abschließen und Ausgeben von solchen Tasks.
In einem kommenden Teil der Serie werden wir uns außerdem anschauen, wie wir dieses Modell erweitern können, und welche Auswirkungen das auf unsere (bis dahin schon funktionale) Anwendung haben wird.
Die Kernfunktionalität: Domain Services
Nun wollen wir uns die gewünschte Funktionalität auf fachlicher Ebene anschauen. Dabei werden wir schnell bemerken, dass wir uns um die ,eigentliche‘ Arbeit an dieser Stelle nur wenige Gedanken machen müssen und diese stattdessen einfach in die Zukunft verschieben können (nämlich in den nächsten Abschnitt, in dem wir uns mit der Datenhaltung in einem Cache befassen werden).
Im Grunde genommen wollen wir drei Grundfunktionalitäten:
- Wir wollen einen neuen Task anlegen können (der im Zustand offen sein soll).
- Wir wollen alle existierenden Tasks abrufen können.
- Wir wollen den Zustand eines Tasks umschalten können.
Das führt uns zu folgenden Methodensignaturen, die wir mit Leben füllen wollen:
Task createTask(String description);
List<Task> getAllTasks();
Optional<Task> toggleCompletionState(UUID id);Hierbei machen wir mit dem Rückgabetypen Optional<Task> in der letzten Methode deutlich, dass diese fehlschlagen kann, wenn kein Task mit der gegebenen ID existiert.
Wie bereits angedeutet, wollen wir einen Großteil der Implementierung in unsere Persistenzschicht (oder genauer, den Persistenzadapter) auslagern. Im Sinne unserer hexagonalen Architektur, die auch als Ports und Adapter bekannt ist, legen wir uns dazu einen Port (in der Form eines Interfaces) an, in dem wir uns wünschen, was ein eventueller Persistenzadapter doch bitte für uns erledigen soll:
package de.colenet.hexagonal.todo.list.domain.service.task;
import ...; // Omitted for clarity
public interface TaskRepository {
Task save(Task task);
Optional<Task> find(UUID id);
List<Task> getAll();
}Solche Ports zählen dabei zur Geschäftslogik und liegen damit auch in unserem Domain Services-Paket. Die Ausimplementierungen der Ports befinden sich hingegen in den entsprechenden Adaptern.
Mithilfe dieses Ports können wir nun unsere eigentliche Serviceklasse anlegen:
package de.colenet.hexagonal.todo.list.domain.service.task;
import ...; // Omitted for clarity
@Service
public class TaskService {
private final TaskRepository taskRepository;
public TaskService(TaskRepository taskRepository) {
this.taskRepository = taskRepository;
}
public Task createTask(String description) {
// TODO
}
public List<Task> getAllTasks() {
// TODO
}
public Optional<Task> toggleCompletionState(UUID id) {
// TODO
}
}Die Ausimplementierung der drei Methoden gestaltet sich jetzt sehr einfach. Zum Erzeugen eines Tasks wollen wir einfach einen neuen, offenen Task mit zufällig generierter ID über den Port anlegen:
public Task createTask(String description) {
return taskRepository.save(new OpenTask(UUID.randomUUID(),description));
}Und das Laden können wir vollständig an den Port delegieren:
public List<Task> getAllTasks() {
return taskRepository.getAll();
}Um den Zustand von Tasks abzuändern, nutzen wir das mit Java 21 neu eingeführte Feature Pattern Matching for switch in Kombination mit Switch Expressions. Außerdem nutzen wir auch hier wieder den Port:
public Optional<Task> toggleCompletionState(UUID id) {
return taskRepository.find(id).map(this::withToggledCompletionState).map(taskRepository::save);
}
private Task withToggledCompletionState(Task task) {
return switch (task) {
case OpenTask t -> new CompletedTask(t.id(), t.description(), LocalDateTime.now(clock));
case CompletedTask t -> new OpenTask(t.id(), t.description());
};
}Hierbei verwenden wir ein Clock clock Objekt, welches wir analog zum Repository über den Konstruktor injizieren, um unseren Code testbar zu halten. Die entsprechende Konfiguration dafür legen wir in einem technischen Modul an:
package de.colenet.hexagonal.todo.list.domain.service.technical.clock;
import ...; // Omitted for clarity
@Configuration
class ClockConfiguration {
@Bean
public Clock clock() {
return Clock.systemDefaultZone();
}
}Testbarkeit ist übrigens einer der großen Vorteile, die uns die gewählte Architektur liefert. Obwohl wir noch keine Implementierung für den Port haben, können wir an dieser Stelle bereits Unittests für unseren Service schreiben, indem wir den Port mocken. Das führt auch automatisch dazu, dass wir uns in diesen Tests rein auf die Fachlichkeit konzentrieren. Das Zusammenspiel der Komponenten werden wir später mittels Integrations- und End-To-End-Tests überprüfen. Da das Testen nicht der Fokus dieser Serie sein soll, werde ich hier nicht tiefer auf die Unittests eingehen. Gerne seid ihr aber dazu eingeladen, euch im begleitenden GitHub Repository die Klasse TaskServiceTest anzuschauen.
Damit steht der Kern unserer Anwendung bereits! Solltet ihr die Anwendung im aktuellen Zustand starten wollen, werdet ihr aber noch keinen Erfolg haben, da derzeit keine Implementierung für TaskRepository existiert. Ihr könnt euch natürlich für den Moment eine Dummy-Implementierung anlegen – oder ihr wartet, bis wir uns gleich dem Cache-Adapter zuwenden.
In-Memory Cache
Zum Abschluss wollen wir also eine konkrete Implementierung für unseren Port TaskRepository in Form eines simplen Caches anlegen. Wie bereits in unserem Architekturtest verankert, wollen wir diese Implementierung im Adapter-Paket de.colenet.hexagonal.todo.list.adapter.cache ablegen. Wir werden an dieser Stelle von jeglichen Optimierungen Abstand halten und stattdessen zu Demonstrationszwecken möglichst einfachen, wenn auch nicht unbedingt produktionsreifen, Code schreiben. Daher entscheiden wir uns dazu, den Adapter als simplen Wrapper um eine Map zu realisieren. Die komplette Implementierung lässt sich damit direkt niederschreiben:
@Repository
class TaskCache implements TaskRepository {
// LinkedHashMap keeps insertion order
private final Map<UUID, Task> tasks = new LinkedHashMap<>();
@Override
public Task save(Task task) {
tasks.put(task.id(), task);
return task;
}
@Override
public Optional<Task> find(UUID id) {
return Optional.ofNullable(tasks.get(id));
}
@Override
public List<Task> getAll() {
return List.copyOf(tasks.values());
}
}Auch hier möchte ich wieder anmerken, dass wir die Implementierung losgelöst von jeglicher Abhängigkeit ganz einfach unit-testen können und auf TaskCacheTest im GitHub Repository hinweisen.
Ausblick
Wir haben bisher eine simple, aber schon funktionale und lauffähige Anwendung entwickelt. Um diese jedoch wirklich nutzen zu können, fehlt uns noch eine Steuerungsmöglichkeit. Daher werden wir die Anwendung im nächsten Teil der Reihe um eine REST-Schnittstelle erweitern, die uns dann die tatsächliche Nutzung ermöglicht.
Alle Folgen der Reihe
„Hexagonale Architektur in der Praxis: Umsetzung in einem Java/Spring-Boot-Projekt“
Teil 1: Projektbeschreibung, Setup und automatische Architekturtests
Teil 2: Modellierung, Kernlogik und In-Memory Cache
Teil 3: REST-Schnittstelle mit Antikorruptionsschicht
Teil 4: Folgen einer Änderung am Domänenmodell und die Applikationsschicht
Teil 5: Anbindung der Datenbank (am Beispiel einer MongoDB)
Fragen, Anmerkungen oder Austausch zum Thema gewünscht?
Nutzt gerne die Kommentarfunktion unter dem Beitrag und Ricardo meldet sich bei euch zurück.