Hexagonale Architektur in der Praxis: Umsetzung in einem Java/Spring-Boot-Projekt – Teil 1: Projektbeschreibung, Setup und automatische Architekturtests
In der Softwareentwicklung gibt es eine Architektur, die seit einigen Jahren immer mehr an Bedeutung gewinnt – die hexagonale Architektur. Ich hatte mehrfach die Gelegenheit, diese Architektur in Kundenprojekten zu realisieren und konnte dabei direkt miterleben, wie sie die Art und Weise, wie wir Software entwickeln, verändert.
In dieser Serie werden wir uns diese Architektur genauer anschauen und ihre Grundprinzipien in der Praxis erleben. Ihr werdet feststellen, dass sie die Anforderungen unserer Benutzer in den Vordergrund stellt und uns gleichzeitig erlaubt, den Code auf eine Weise organisieren zu können, die sowohl robust als auch flexibel ist. Damit trägt sie erheblich zur Wartbarkeit, Erweiterbarkeit und Testbarkeit unserer Anwendungen bei.
Wir werden uns anschauen, wie sich eine hexagonale Architektur in einer typischen Webanwendung praktisch realisieren lässt. Dazu werden wir Schritt für Schritt eine kleine To-do-Listen-Anwendung entwickeln, die es ermöglichen soll, Tasks anzulegen, angelegte Tasks anzuzeigen und Tasks als erledigt zu markieren. Die Anwendung wird über eine REST-Schnittstelle bedienbar sein und die Tasks werden konfigurierbar entweder In-Memory oder persistent in einer echten MongoDB verwaltet.
Zum Einstieg möchte ich kurz darauf eingehen, was gemeint ist, wenn wir von einer hexagonalen Architektur sprechen.
Hexagonale Architektur – was ist das überhaupt?
Es handelt sich hierbei um einen Architekturstil, der unter vielen Namen bekannt ist: hexagonale Architektur, Ports und Adapter, Zwiebelarchitektur (Onion Architecture), Clean Architecture
All diese Architekturstile unterscheiden sich im Detail, basieren aber auf denselben Kernideen und Prinzipien. Auf die feinen Unterschiede möchte ich an dieser Stelle nicht genauer eingehen, sondern verweise auf die zahlreichen, online verfügbaren Ressourcen zu diesem Thema, wie etwa den hervorragenden Übersichtsartikel von Herberto Graça (englisch).
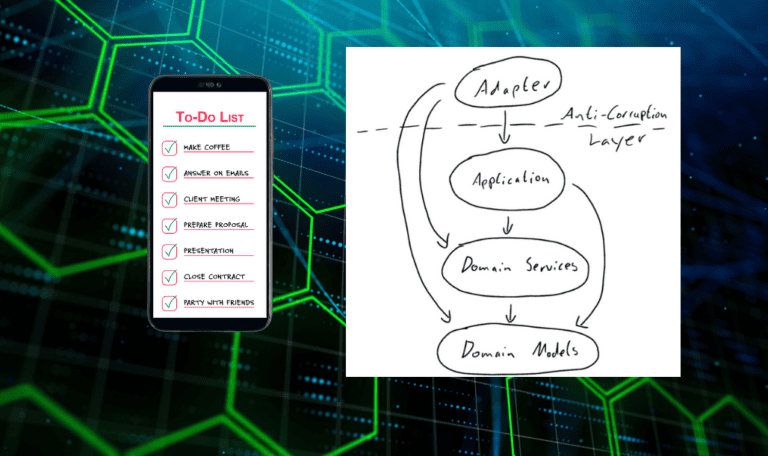
In dieser Serie werde ich die Unterschiede unterschlagen und die Begriffe hexagonale Architektur und Zwiebelarchitektur synonym verwenden. Wir verstehen darunter eine Anwendungsarchitektur, die den Code in konzentrischen Schichten (daher der Name Zwiebel) organisiert. Hierbei sind nur Abhängigkeiten von außen nach innen gestattet (es dürfen dabei aber Schichten übersprungen werden), sodass insbesondere die innerste Schicht keinerlei Abhängigkeiten auf den Rest des Codes haben darf. Genauer unterteilen wir die Anwendung in die folgenden drei, von innen nach außen angeordneten Schichten:
- Domänenschicht: Beinhaltet die Domänenmodelle und die Kerngeschäftslogik.
- Anwendungsschicht: Ist verantwortlich für anwendungsinterne Aufgaben, die nicht der Kernlogik zuzuordnen sind. Hierzu gehören etwa die Ausführung von geplanten Aufgaben, Transaktionssteuerung oder auch das Zusammenführen mehrerer Teile der Kernlogik zu einem Workflow.
- Adapterschicht: Handhabt jegliche Interaktion der Anwendung mit der Außenwelt, wie etwa die Bereitstellung von API-Endpunkten, Durchführung von Datenbankzugriffen oder die Kommunikation mit anderen Schnittstellen.
Die Domänenschicht lässt sich dabei noch in zwei weitere Teilschichten zerlegen: Modelle (innen) und Logik (außen). Außerdem kann die Adapterschicht aus mehreren, voneinander unabhängigen, Adaptern bestehen (nämlich ein Adapter je Anlass). Das Modell lässt sich also folgendermaßen visualisieren:
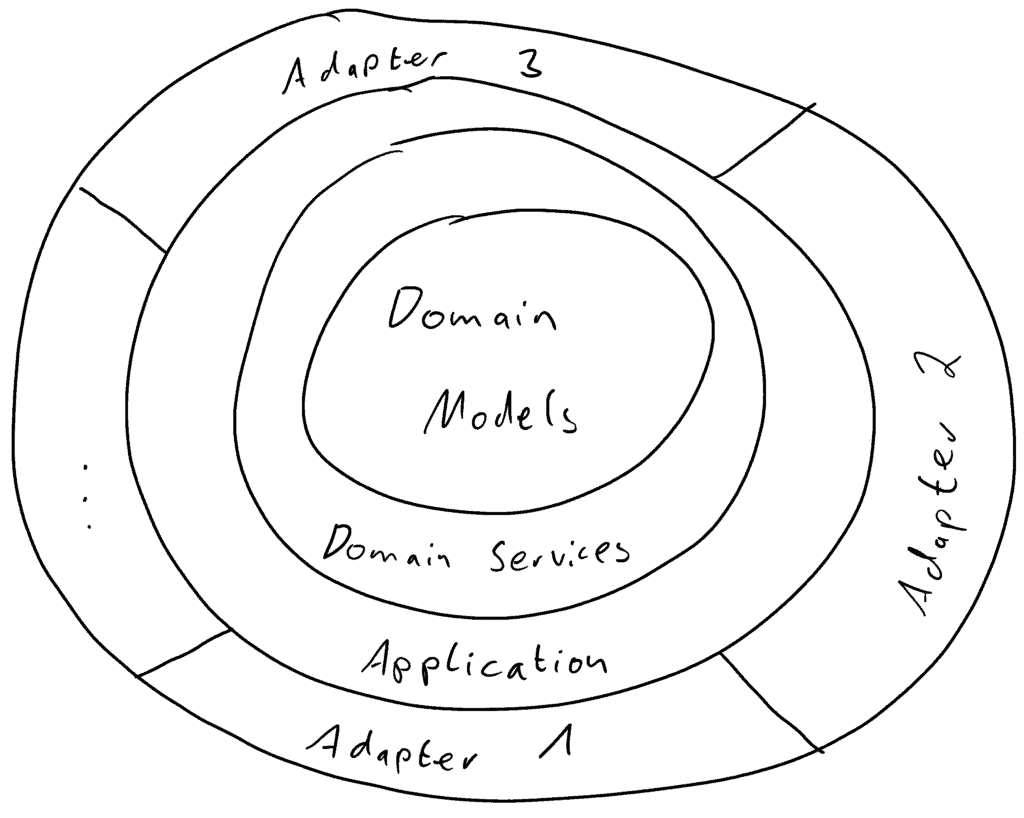
Die Zwiebelarchitektur liefert eine Reihe von Vorteilen, etwa:
- Domänenzentriertes Design: Die Kerngeschäftslogik wird gegenüber von Infrastrukturangelegenheiten klar in den Fokus gesetzt.
- Testbarkeit: Die Kerngeschäftslogik ist isoliert und kann dadurch mittels Unittests losgelöst von jeglichen Abhängigkeiten getestet werden. Selbiges trifft auch auf die anderen Schichten zu.
- Flexibilität: Änderungen an externen Technologien oder Schnittstellen beschränken sich auf die Adapterschicht und wirken sich minimal (im besten Fall gar nicht) auf die Kerngeschäftslogik aus.
- Wartbarkeit: Die Schichten kommunizieren über wohldefinierte Schnittstellen und ermöglichen es daher, bestimmte Komponenten zu aktualisieren oder auszutauschen, ohne den Rest der Anwendung zu beeinträchtigen.
- Klare Projektstruktur: Die schichtweise Struktur lässt sich intuitiv auf die Organisation des Projekts übertragen.
Mit diesem Verständnis können wir nun in die Umsetzung unseres Beispielprojekts starten.
Projektsetup
Wir starten mit einem neu initialisierten Spring Boot Projekt basierend auf Java 21, welches wir mit Maven (via Maven Wrapper) verwalten. Darüber hinaus verwenden wir Prettier Java für eine einheitliche Formatierung, Renovate für (semi-)automatisierte Dependency-Updates, sowie GitHub Actions für automatisierte CI-Builds. Damit sieht unsere Anwendung zum Start folgendermaßen aus:
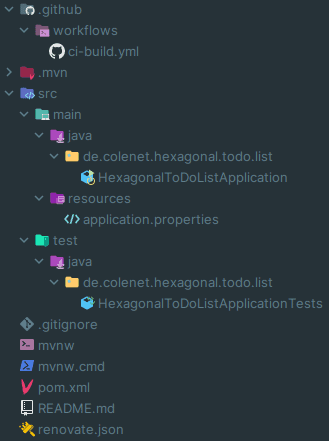
Da wir zu diesem Zeitpunkt keinerlei Anwendungskonfiguration haben, ist die Datei application.properties leer und unsere Einstiegsklasse startet bisher lediglich die Anwendung:
@SpringBootApplication
class HexagonalToDoListApplication {
public static void main(String[] args) {
SpringApplication.run(HexagonalToDoListApplication.class, args);
}
}Etwas interessanter ist unsere Mavenkonfiguration pom.xml. Hier binden wir schon einige Abhängigkeiten ein, die wir im Laufe der Entwicklung verwenden wollen (die Abhängigkeit spring-boot-starter-data-mongodb lassen wir hier noch auskommentiert, da ansonsten die Anwendung ohne zusätzliche Konfiguration nicht starten würde) und konfigurieren Prettier. Die vollständige POM sowie das gesamte Projekt könnt ihr auf GitHub finden.
Geplante Paketstruktur
Wir orientieren uns hier an dem eingangs dargestellten Zwiebelmodell. Dieses Modell können wir in unserem Java-Code exakt in eine Paketstruktur übersetzen. Gehen wir davon aus, dass unsere Anwendung im Basispaket base (für unsere konkrete Anwendung ersetze base durch de.colenet.hexagonal.todo.list) liegt, so kann eine Paketstruktur folgendermaßen aussehen:
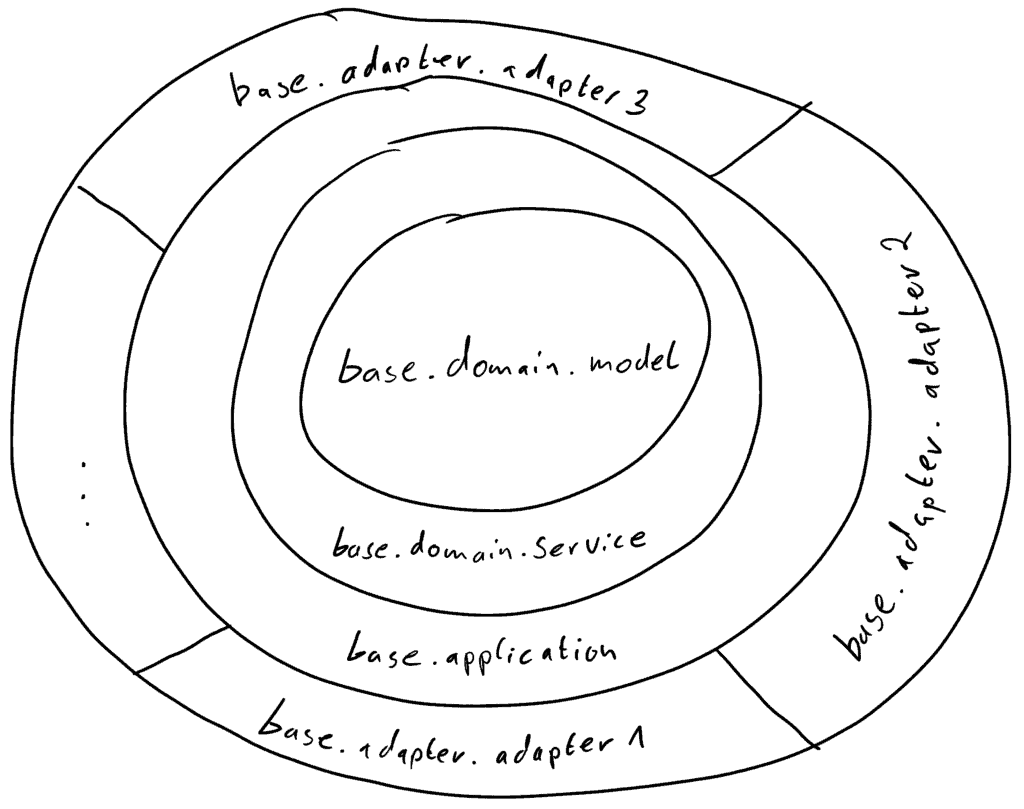
Zur Erinnerung: Für die Schichten der Zwiebel gilt hierbei, dass Zugriffe nur von außen nach innen gerichtet erlaubt sind. Schichten dürfen dabei aber übersprungen werden.
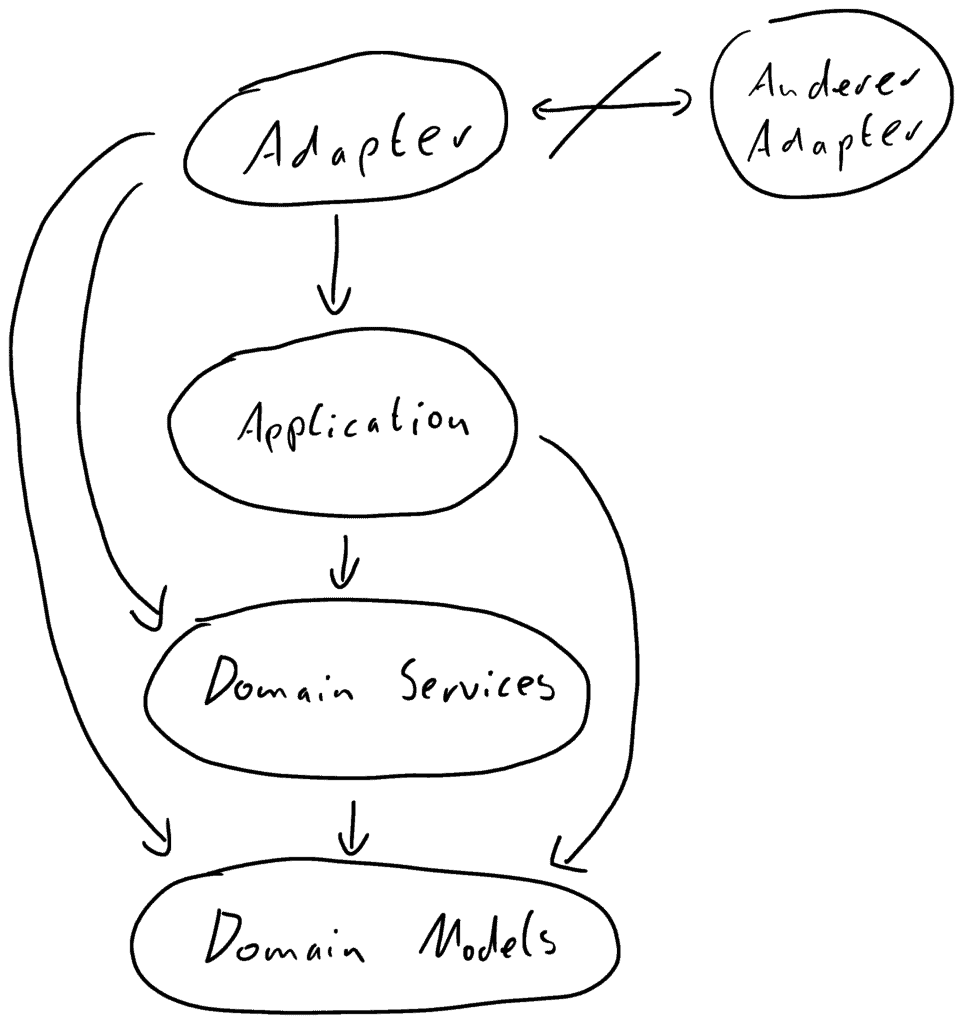
Insbesondere ist es verschiedenen Adaptern nicht erlaubt, sich gegenseitig aufzurufen, auch wenn sie in derselben Schicht dargestellt sind.
Genau diese Struktur und Zugriffsrechte wollen wir in unserem Projekt automatisiert sicherstellen. Dazu schreiben wir im nächsten Abschnitt einen Architektur-Unittest, der, wie alle anderen Unittests, bei jedem CI-Build ausgeführt wird und den Build bei einer Verletzung unserer Regeln fehlschlagen lässt.
Architektur-Unittests
Hierzu verwenden wir ArchUnit, eine Java Bibliothek, die
sich selbst beschreibt als: ArchUnit is a free, simple and
extensible library for checking the architecture of your Java code using
any plain Java unit test framework. Konkret bedeutet das für uns,
dass ArchUnit es uns erlaubt, normalen Java-Testcode zu schreiben und
diese Tests dann mit JUnit auszuführen. Eine simple Testklasse muss dazu
einzig mit @AnalyzeClasses annotiert werden. Außerdem
müssen Testfälle mit der Annotation @ArchTest
gekennzeichnet werden. Für mehr Details verweise ich gerne auf die
hervorragende Dokumentation
von ArchUnit.
Unsere Testklasse wird damit folgendermaßen aussehen:
@AnalyzeClasses(packages = "base", importOptions = ImportOption.DoNotIncludeTests.class)
class HexagonalArchitectureTest {
@ArchTest
static final ArchRule onionArchitectureIsRespected = ... // TODOAuffällig ist hierbei eventuell die Konfiguration importOptions = ImportOption.DoNotIncludeTests.class, die Testklassen von unserem Architekturtest ausschließt. Dazu habe ich mich entschieden, um beim Testen etwas mehr Flexibilität zu bewahren. Ihr könnt diese Option in eurer Anwendung natürlich außen vor lassen, um noch strikter zu sein.
Um unseren Test zu vervollständigen, verwenden wir die von ArchUnit von Haus aus bereitgestellte Onion Architecture Regel:
@ArchTest
static final ArchRule onionArchitectureIsRespected = Architectures
.onionArchitecture()
.domainModels("base.domain.model")
.domainServices("base.domain.service")
.applicationServices("base.application")
.adapter("adapter1","base.adapter.adapter1")
.adapter("adapter2","base.adapter.adapter2")
// ... more adapters
.ensureAllClassesAreContainedInArchitectureIgnoring("base");Wir ignorieren der Einfachheit halber alle Klassen, die direkt in unserem Basispaket liegen, da sich dort aus technischen Gründen unsere mit @SpringBootApplication annotierte Einstiegsklasse befindet. In einer Produktivanwendung könnten wir hier mittels eines DescribedPredicate genauer sein und nur diese eine Einstiegsklasse vom Test ausschließen.
Für unseren Fall müssen wir nun natürlich das korrekte Basispaket verwenden und konkrete Adapter definieren. Hier wollen wir für den Moment mit den Adaptern cache und rest starten. Außerdem setzen wir temporär die Option withOptionalLayers(true) um leere Schichten zu erlauben.
@AnalyzeClasses(packages = HexagonalArchitectureTest.BASE_PACKAGE, importOptions = ImportOption.DoNotIncludeTests.class)
class HexagonalArchitectureTest {
static final String BASE_PACKAGE = "de.colenet.hexagonal.todo.list";
@ArchTest
static final ArchRule onionArchitectureIsRespected = Architectures
.onionArchitecture()
.domainModels(getPackageIdentifier("domain.model"))
.domainServices(getPackageIdentifier("domain.service"))
.applicationServices(getPackageIdentifier("application"))
.adapter("cache", getAdapterIdentifier("cache"))
.adapter("rest", getAdapterIdentifier("rest"))
.withOptionalLayers(true) // TODO Remove this as soon as our layers are filled
.ensureAllClassesAreContainedInArchitectureIgnoring(BASE_PACKAGE);
private static String getAdapterIdentifier(String name) {
return getPackageIdentifier("adapter." + name);
}
private static String getPackageIdentifier(String subpackage) {
return BASE_PACKAGE + "." + subpackage + "..";
}
}Ausblick
Im nächsten Teil dieser Serie füllen wir unsere Anwendung mit erster Funktionalität. Dazu werden wir einen Service aufsetzen, der es uns erlaubt, Tasks anzulegen, auszulesen und als abgeschlossen zu markieren. Die Daten werden wir für den Anfang in einem In-Memory Cache halten. In einem späteren Beitrag werden wir diesen dann durch eine echte Datenbank ersetzen.
Alle Folgen der Reihe
„Hexagonale Architektur in der Praxis: Umsetzung in einem Java/Spring-Boot-Projekt“
Teil 1: Projektbeschreibung, Setup und automatische Architekturtests
Teil 2: Modellierung, Kernlogik und In-Memory Cache
Teil 3: REST-Schnittstelle mit Antikorruptionsschicht
Teil 4: Folgen einer Änderung am Domänenmodell und die Applikationsschicht
Teil 5: Anbindung der Datenbank (am Beispiel einer MongoDB)
Fragen, Anmerkungen oder Austausch zum Thema gewünscht?
Nutzt gerne die Kommentarfunktion unter dem Beitrag und Ricardo meldet sich bei euch zurück.