Wann ist die Software endlich fertig? Wie du diese Frage professionell beantwortest
Die Antwort auf die Frage im Titel hängt ganz davon ab, wie wir die Arbeit an der Software klassifizieren.
Pauschal können wir nicht sagen:
- „Softwareentwicklung lässt sich nicht schätzen. Sie ist fertig, wenn sie fertig ist.“
- „Für die Umsetzung benötigen wir 165 Tage.“
- „Das erledige ich sofort, es geht in einer Stunde live.“
In bestimmten Situationen treffen diese Antworten zu, in anderen entsprechen sie eher Wunschdenken oder Fantasie. Es hängt davon ab, um welche Art von Arbeit es sich handelt. Erst wenn wir eine korrekte Klassifizierung gewählt haben, sind wir in der Lage, die Methode zur zeitlichen Bestimmung auszuwählen, die uns wirklich weiterhilft.
Lasst uns das einmal näher betrachten.
Verschiedene Arten von Softwareentwicklungsarbeit
Nach meinem Studium arbeitete ich als Softwareentwickler. Dabei wurde mir schnell eines klar: Es gibt zwei extreme Typen von Arbeit.
Extrem 1: Einfache Feature-Entwicklung (oder: ein Fall wie viele andere)
Eines meiner ersten Projekte war die Entwicklung von Software zur Steuerung von Haushaltsgeräten.
Da viele Basisfunktionen der Software bereits entwickelt waren, bestand eine meiner Aufgaben darin, diese zu erweitern. Ich fügte der bestehenden Funktionalität eine Log-Funktion hinzu, die es ermöglichte, die Software im Testbetrieb detailliert zu überwachen.
Die Integration der Log-Funktion gestaltete sich jedes Mal gleich:
- Einbindung des Aufrufs der Log-Funktion in das Feature.
- Übergabe der relevanten Variablen an dieses Feature.
- Setzen der passenden Compiler-Flags.
- Überprüfung, ob die Variablen mitgeschrieben werden.
- Abschließende Anpassung der Dokumentation des Features.
- Begutachtung meiner Arbeit durch einen Kollegen.
- Zusammenführung der Änderungen in den aktuellen Branch.
Die Erweiterung eines Features um eine Log-Funktion dauerte etwa einen Tag. Das konnte ich garantieren. Denn anders als in vielen Frameworks ist eine Log-Funktionalität in der Programmiersprache „C“ zwar nicht enthalten, aber die Implementierung ist so weit verbreitet, dass die Umsetzung in Entwicklerforen nachzulesen ist. Stieß ich dennoch auf ein Problem, konnte ich mich jederzeit an meine Kollegin wenden, die die Log-Funktionalität nicht nur entwickelt, sondern auch dutzendfach in andere Software integriert hatte.
Neben der Erweiterung von Features arbeitete ich auch an:
Extrem 2: Fehlerbehebung (oder: die Wundertüte)
Manchmal bearbeitete ich auch Tickets, die aus dem Systemtest zurückkamen.
Bevor die Software für die Nutzung durch Kunden freigegeben wurde, musste sie den Systemtest bestehen. Im Systemtest wurde die Software im echten Betrieb getestet, was bedeutete: Nasse Wäsche wurde in die Waschmaschinen gegeben und Programm für Programm getestet; diese Schritte wurden mehrmals wiederholt. Scheiterte der Systemtest, wurde ich mit einem Ticket darüber informiert.
Dieses Ticket konnte alles bedeuten.
Was auch immer das Problem lösen würde, konnte ich nirgends nachlesen. Da nur eine Handvoll Unternehmen weltweit in diesem Bereich produzieren, fand ich auch dazu nichts in Entwicklerforen. Und obwohl viele meiner Kollegen schon lange Software entwickelten, kannten sie die neuesten Features, die häufig das Problem verursachten, meistens noch nicht.
Auf mich allein gestellt ging ich so vor:
- Zuerst versuchte ich, den Fehler auf meinem Rechner mit einem Prototyp nachzustellen.
- Konnte der Fehler nicht reproduziert werden, versuchte ich, den Fehler im Labor zu simulieren.
- Gelang mir das nicht, bat ich die Kollegen aus dem Dauerlauf um Hilfe, in der Hoffnung, den Fehler unter realen Bedingungen nachstellen zu können. Diese Bedingungen entsprechen dem Systemtest.
- Konnte ich den Fehler immer noch nicht finden, musste ich mich direkt an den Systemtest wenden.
Die Fehlersuche kann sehr zeitintensiv sein:
Während die Simulation am Rechner eine Sache von Stunden ist, nimmt der Test im Labor einige Tage in Anspruch. Ein erneuter Systemtest bedeutet einen Aufwand von mehreren Wochen, da viele der Systemtests im Ausland durchgeführt werden. Und das sind nur die Zeiten, um den Fehler zu finden; die Zeit zur Behebung des Fehlers kommt noch hinzu. Was und wie viel Code angepasst werden muss, konnte ich erst einschätzen, wenn der Fehler gefunden war.
Wie lange es am Ende dauerte, ließ sich niemals vorhersagen, wenn das Ticket in meinem Posteingang auftauchte.
Was sind die Merkmale dieser verschiedenen Extreme von Softwareentwicklungsarbeit?
Ich habe diese beiden Beispiele gewählt, da sie zwei Extreme beschreiben, die die Arbeit in der Softwareentwicklung annehmen kann.
Zusammenfassend beschreibe ich sie wie folgt:
Extrem 1: Ein Fall wie viele andere (z.B. die Erweiterung einfacher Features)
- Mehrere Teammitglieder haben die Expertise, um die Arbeit durchzuführen.
- Nach der Analyse lässt sich ein Plan zur Lösung einfach erstellen und Schritt für Schritt umsetzen.
- Diese Voraussetzungen machen die Arbeit planbar und das Ende lässt sich gut abschätzen.
Extrem 1: Die Wundertüte (z.B. Fehlerbehebung)
- Unklarheit, ob die eigene Expertise oder die des Teams ausreicht, um das Problem zu lösen.
- Viele Unbekannte verhindern die Zerlegung des Problems und eine Detailanalyse.
- Versuche, die Situation nachzustellen, werden notwendig.
- Dabei entstehen u.U. Abhängigkeiten zu anderen Abteilungen.
- Diese Punkte machen den zeitlichen Ablauf der Arbeit unplanbar.
Die meiste Arbeit, die Softwareentwickler erledigen, spielt sich wahrscheinlich irgendwo zwischen diesen Extremen ab. So liegt die Neuentwicklung eines Features etwa irgendwo zwischen der Erweiterung eines bestehenden Features (Extrem 1) und dem Aufspüren eines völlig unbekannten Fehlverhaltens der Anwendung (Extrem 2).
Um nun auch andere Arten von Arbeit auf diese Art einzuordnen, hat sich eine einfache Skala bewährt.
Eine Skala zur Klassifizierung von Softwareentwicklungsarbeit
Diese einfache Skala geht meines Wissens auf Liz Keogh zurück.
Du verwendest sie wie folgt: Möchtest du die Arbeit, die dein Team zu erledigen hat, klassifizieren, dann bitte dein Team, dem Eintrag im Product Backlog eine Zahl von 1 bis 5 zuzuordnen.
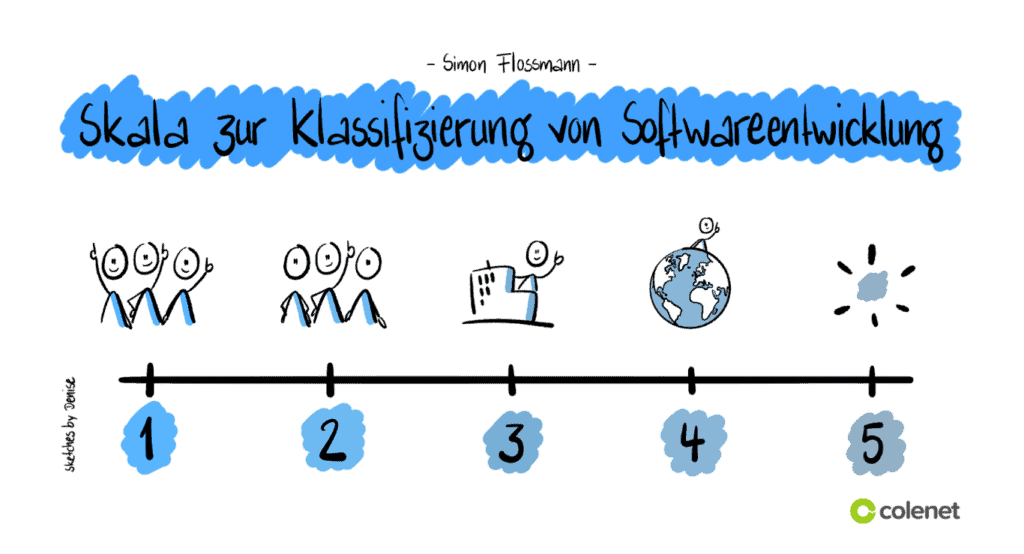
Hierbei bedeutet:
- Wir alle wissen, wie man das macht.
- Jemand in unserem Team weiß, wie es gemacht wird.
- Jemand in unserem Unternehmen hat es bereits gemacht oder wir haben Zugang zu Fachexperten.
- Jemand auf der Welt hat dies bereits gemacht, aber nicht in unserem Unternehmen (und wahrscheinlich bei einem Konkurrenten).
- Wir glauben, dass niemand auf der Welt dies jemals zuvor gemacht hat.
Mein Beispiel der Weiterentwicklung eines Features (Extrem 1) entspricht einer Eins auf der Skala. Und die Behebung eines unbekannten Fehlers (Extrem 2) entspricht eher einer Drei oder Vier.
Vorhersagen in der Softwareentwicklung: Wann ist das Feature fertig?
Mit dieser Skala erkennst du sofort, dass es keine pauschale Antwort auf folgende Fragen gibt:
- Wie lange dauert die Umsetzung?
- Wann ist das Feature fertig?
- Wann kann ich dem Kunden sagen, dass der Fehler behoben sein wird?
- Was ist der Zeithorizont dieses Softwareprojekts?
- Werden wir die Deadline für dieses Projekt einhalten können?
Die Antwort auf diese Fragen hängt davon ab, wie wir die Arbeit klassifizieren.
Die Antwort „Das erledige ich sofort, es geht in einer Stunde live.“ ist wahrscheinlich zutreffend, wenn wir von Arbeiten der Klasse Eins sprechen. Hingegen trifft die Antwort „Softwareentwicklung lässt sich nicht schätzen. Sie ist fertig, wenn sie fertig ist.“ bei Product-Backlog-Einträgen der Klasse Vier zu.
Wenn wir die Vorhersagegenauigkeit steigern und damit das Vertrauen der Stakeholder in unser Team stärken wollen, sollten wir die verschiedenen Product-Backlog-Einträge keinesfalls als gleichwertig betrachten..
Stimmst du damit überein, findest du im Folgenden drei unterschiedliche Ansätze, die du je nach Klassifikation von Einträgen im Product-Backlog verwenden kannst, um Vorhersagen zu treffen.
Unterschiedlich klassifizierte Arbeiten erfordern unterschiedliche Schätzmethoden
Schätzmethode 1: Absolute Schätzung für Arbeit der Klasse Eins
Für Einträge im Product-Backlog, die die Entwickler des Scrum Teams mit „Eins“ bewerten, könnte eine absolute Zeitschätzung verwendet werden. Etwa: Für die Umsetzung dieses Eintrags benötigt Tom ungefähr 7 Stunden. Diese Arbeit entspricht meinem Beispiel für die Erweiterung eines bestehenden Features, das ich bereits mehrfach umgesetzt habe. Bei solchen Arbeiten ist es durchaus wahrscheinlich, dass die Prognose zutrifft, wann der Eintrag abgeschlossen sein wird.
Befindet sich die Arbeit eher an der Grenze zu „Jemand in unserem Team weiß, wie es gemacht wird“, dann ist es sinnvoll, die Prognose um einen Risikozuschlag zu erweitern, wie etwa geschätzte Arbeitszeit plus 25 %.
Schätzmethode 2: Relative Schätzung für Arbeit der Klasse Zwei
Für Einträge im Product-Backlog, die die Entwickler des Teams mit „Zwei“ bewerten, sollte eine relative Schätzung verwendet werden. Bei relativen Schätzungen wird nicht die absolute Zeit als Schätzung angegeben, sondern die Einträge werden in Relation zueinander gestellt und einem Referenzeintrag zugeordnet. Die Einheit, in der dann geschätzt wird, ist häufig eine fiktive Größe wie Story Points, Gummibären, Same-Sizing oder T-Shirt-Größen.
Das relative Schätzen erlaubt es, den Grad an Unsicherheit und Nicht-Wissen bei Arbeiten der Klasse Zwei einzubeziehen und in der Schätzung zu kommunizieren.
Schätzmethode 3: Timeboxing für Arbeit der Klasse Drei oder höher
Bei Arbeiten, die die Entwickler des Scrum-Teams als Klasse Drei oder höher einstufen, liefern auch relative Methoden zur Schätzung nur noch wenig verlässliche Prognosen.
Diese Arbeit zeichnet sich dadurch aus, dass nur wenig bekannt ist und die Expertise — falls sie existiert — nicht mehr im Team liegt. Hier sollte nicht mehr geschätzt, sondern budgetiert werden.
Budgetierung bedeutet, dass das Team eine feste Zeit bestimmt, die es investieren will, um an diesem Problem zu arbeiten. Dies mag zunächst befremdlich klingen. Wir sollten jedoch nicht vergessen, dass es keine Garantie gibt, dass Arbeit, die ein Problem der Klasse Fünf angeht, jemals zu einem lieferbaren Ergebnis führt. Es ist durchaus wahrscheinlich, dass die Zeit nur investiert wird, damit das Team lernt, dass dieser Ansatz nicht funktioniert. Und diese zeitliche Investition sollte begrenzt werden. Wir tun dies, indem wir uns eine Timebox setzen, die wir investieren wollen, um mehr über die Problemstellung zu lernen, auszuprobieren, welcher Lösungsweg funktionieren kann, oder zu erfahren, ob der Ansatz die Nutzer begeistert.
Die bekannteste Timebox ist wohl der Sprint. Er begrenzt die Arbeit, die ein Scrum-Team unternimmt, auf maximal einen Monat. Spätestens nach einem Monat muss ein Scrum-Team mit den Stakeholdern des Produkts zurückblicken und reflektieren, ob die Arbeit das Team einen Schritt weiter bei der Erreichung des Produkt-Ziels gebracht hat.
Bei der Schätzung von Arbeiten ab Klasse Vier kann es bedeuten, dass das Scrum-Team einen Sprint investiert, um bei einer aktuellen Herausforderung Resultate zu erzielen. Diese Herausforderung kann dann in Form eines Sprint-Ziels mit den Stakeholdern geteilt werden. Im Review wird der Fortschritt bei der Erreichung dieses Ziels besprochen, und zusammen mit den Stakeholdern entscheidet der Product Owner, ob das Ergebnis ausreicht, ob noch ein weiterer Sprint investiert werden soll, oder ob sich das Team lieber einem anderen Problem widmen sollte.
Darin besteht der Sinn von Sprints: Sie beschränken das Investitionsrisiko, welches ein Unternehmen eingeht, auf einen Monat.
Wir finden die Idee, komplexe Arbeit der Klasse Drei oder mehr zeitlich zu begrenzen, auch noch in anderen Methoden — etwa in Design-Sprints, Spikes oder UX-Research-Projekten. Der Zweck dieser Methoden ist es, etwas zu lernen, dafür aber nur eine festgelegte Zeit zu investieren.
Appell: Differenzierung ist bei zeitlichen Prognosen unbedingt gefragt – Pauschalität ist kein Werkzeug für Profis
Für Menschen, die nur einen Hammer kennen, sieht alles aus wie ein Nagel. Sie merken erst, dass es nicht funktioniert, wenn sie das Gewinde der Schraube kaputtgeklopft haben.
Einen Profi zeichnet aus, dass er Probleme differenzieren und aus einer Bandbreite an Werkzeugen wählen kann. In der Softwareentwicklung bedeutet professionelles Handeln, keine pauschalen Antworten zu geben, sondern innezuhalten und die Situation einzeln zu betrachten, die richtigen Werkzeuge auszuwählen und dann eine glaubhafte Vorhersage darüber zu treffen, wann die Arbeit abgeschlossen sein kann. Profi zu sein bedeutet auch, den Mut zu haben, dies zu tun, auch wenn die Antwort deinem Gegenüber zunächst nicht zusagen wird.
Bist du ein Profi? In welchen Situationen fällt es dir schwer?




Hallo Sebastian!
Danke für deine Einsicht. Ich finde, du bringst es schon auf den Punkt: Die zeitliche Abschätzung, beantwortet dir nicht, wann es fertig sein wird. 💯
Sehr interessanter Artikel :), der beschreibt, wie ein Team den Arbeitsaufwand schätzen kann. Dies ermöglicht – zumindest für jeweils einzelne Arbeitspakete (Items) – einen mehr oder weniger ungefähren Zeithorizont. Leider berücksichtigt eine Schätzung (in Stunden, Story Points, Budgets, etc.) nicht die internen Schleifen und/oder Abhängigkeiten, so dass selbst mit einer sehr akkuraten Schätzung die tatsächliche Verweildauer der Items im „Flow“ nicht gut vorhergesagt werden kann (wenn bspw. die Flow Effizienz sehr niedrig ist).
Ich persönlich gehe mehr und mehr dazu über, auch die historischen (Flow) Daten mit zu berücksichtigen. Damit lassen sich anhand von Verteilungen (Perzentilen) für einzelne Items auch Single-Item-Prognosen mit einer gewissen Konfidenz und einem Bereich erstellen (z.B. in der Vergangenheit wurden 85% der Items innerhalb von 10 Tagen fertig => jedes Item hat bei etwa gleichen Bedingungen eine Wahrscheinlichkeit von 85% innerhalb von 10 Tagen oder früher fertig zu werden). Hier lassen sich natürlich für unterschiedlich große Items auch unterschiedliche Daten heranziehen.
Um die Abarbeitung vieler Items, die gleichzeitig bearbeitet werden, vorherzusagen, nutze ich dann Monte Carlo Simulationen, welche den historischen Durchsatz berücksichtigen (z.B. mit einem ähnlichen Durchsatz der letzten 80 Tage und einer Konfidenz von 85% werden im nächsten Sprint 30 Items oder mehr fertig; bzw. werden unsere 100 offenen Tickets bis zum 01.04. oder früher fertig).
Das bedeutet nicht, dass Schätzungen nicht wertvoll sind, insbesondere, wenn es darum geht, ein gemeinsames Verständnis zu den jeweiligen Items zu bekommen (z.B. „Warum hast du 3 SP geschätzt, während ich hier 13 SP sehe?“).