Warum sich Product Owner bei der Bearbeitungsdauer von Features nicht auf die durchschnittliche Velocity verlassen sollten und was sie stattdessen tun können
Wann ist das Feature fertig?
Diese legitime Frage, die Stakeholder im Sprint Review stellen und welche regelmäßig Mitglieder des Scrum Teams zusammenzucken lässt, sollte jeder erfahrene Product Owner beantworten können.
Im Folgenden findest du Möglichkeiten, wie du diese Frage beantworten kannst. Diese Antworten haben sich bereits in der Praxis vieler Product Owner bewährt. Deshalb gebe ich sie auch in meinen Professional Scrum Trainings weiter.
Nehmen wir einmal an, das Feature, nach dem sich der Stakeholder erkundigt, besteht aus den ersten fünf grünen Einträgen im Product Backlog.
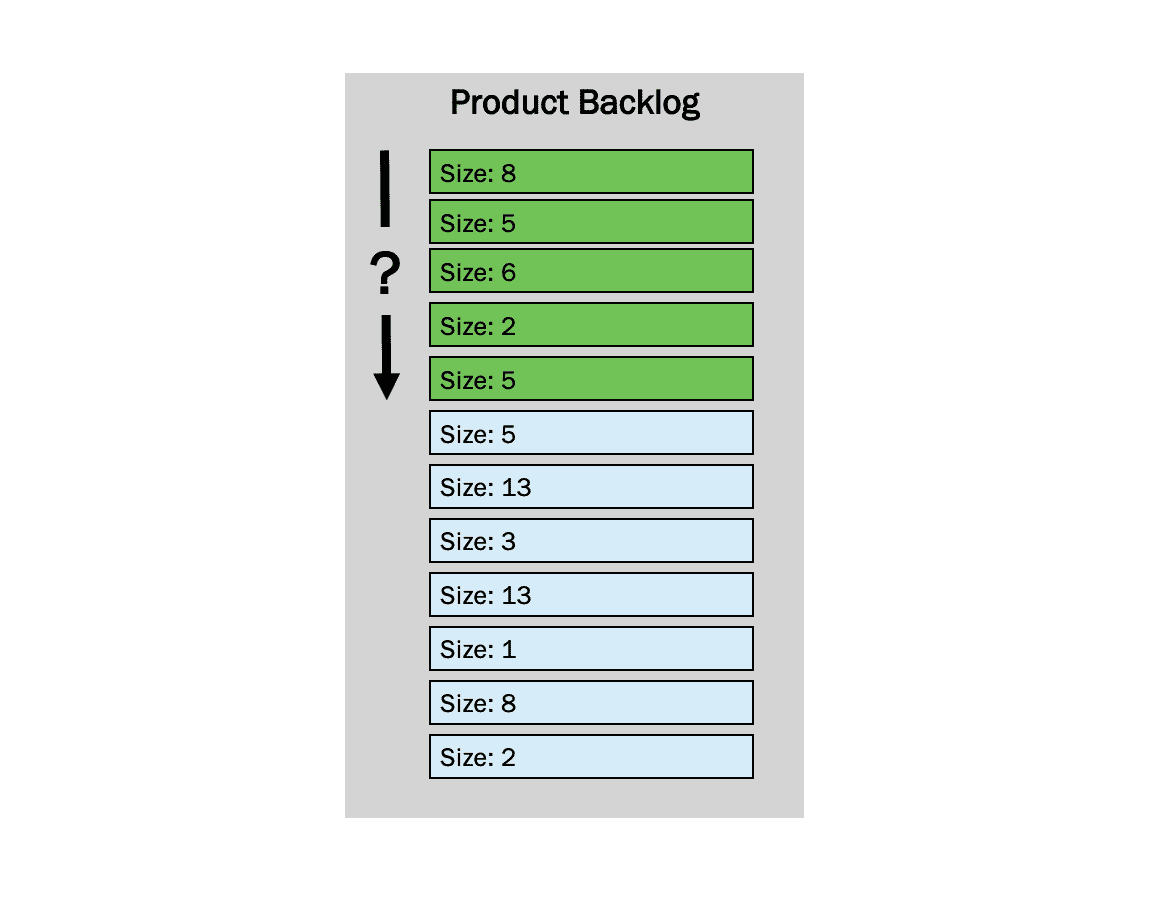
In den letzten drei Sprints hat das Scrum Team einmal 10 Story Points, dann 20 Story Points und im letzten 8 Story Points erledigt. Im Durchschnitt also etwa 13. Beantwortet man die Frage, wann das Feature fertig ist, basierend auf dem Durchschnitt, lautet die Antwort „in zwei Sprints“.
Diese Antwort ist allerdings in 1 von 32 Fällen richtig.
Warnung #1: Beantworte die Frage nicht basierend auf der durchschnittlichen Velocity
Warum ist das so?
Der Informatiker und Statistiker Dr. Sam L. Savage erklärt es in seinen Vorträgen wie folgt: Angenommen, es findet um 8:00 Uhr eine Besprechung statt, zu der 5 Personen eingeladen sind. Es müssen alle Teilnehmer anwesend sein, bevor die Besprechung beginnen kann. Nehmen wir weiter an, dass alle Teilnehmer im Durchschnitt pünktlich zu den Besprechungen erscheinen und dass die durchschnittliche Pünktlichkeit 50 % beträgt.
Was sind die Chancen, dass die Sitzung pünktlich beginnt?
Wenn im Durchschnitt alle Teilnehmer pünktlich erscheinen, könnte man davon ausgehen, dass die Besprechung mit einer durchschnittlichen Wahrscheinlichkeit pünktlich beginnen wird. Leider ist auch diese Antwort falsch.
Warum ist das so?
Wir können uns dies anhand von Münzwürfen erklären: Da jeder Eingeladene eine 50-prozentige Chance hat, pünktlich zu erscheinen, könnten wir das wie folgt auffassen: Ist ein bestimmter Teilnehmer pünktlich erschienen, bedeutet diese „Kopf“, sonst „Zahl“. Wenn wir jetzt berücksichtigen, dass die Besprechung nur dann beginnen kann, wenn alle Teilnehmer eintreffen, bedeutet das, dass wir 5 Mal in Folge Kopf werfen müssen. Diese Wahrscheinlichkeit beträgt (1/2)^5, also etwa 1 zu 32.
Der Durchschnitt ignoriert Unsicherheiten.
Wenn man die Beantwortung der Frage „Wann wird das Feature fertig sein?“ nur auf eine einzige Zahl reduziert, ignoriert man alle Unbekannten und die Variabilität, die bei der Entwicklung des Features auftreten können. Erfahrene Product Owner beziehen die in der Produktentwicklung herrschende Unsicherheit in ihre Antwort mit ein.
Antwort #1: Basierend auf dem Kegel der Unsicherheiten
Sie bedienen sich dabei einem Vorgehen, welches sich in der Vorhersage von Hurrikans im Katastrophenschutz bewährt hat. Projiziert man Hurrikanvorhersagen auf eine Landkarte, sieht es ungefähr so aus wie ein Kegel. Der mögliche Korridor des Hurrikans ist zunächst recht eng und wird immer breiter, je weiter man in die Zukunft schaut. Meteorologen berechnen den Kegel anhand mathematischer Modelle, die die bisher gesammelten Wetterdaten berücksichtigen.
Als Product Owner können wir uns das Vorgehen zunutze machen, um die Unsicherheit in unserer Vorhersage zu visualisieren.
Die untere Seite des Kegels (grüne gestrichelte Linie) entspricht der Velocity von 20 aus dem zweiten Sprint. Die obere Seite des Kegels (rote gestrichelte Linie) entspricht der Velocity von 8 aus dem dritten Sprint. Der dadurch aufgespannte Kegel beschreibt basierend auf der vergangenen Fertigstellungsgeschwindigkeit, dass das Feature im besten Fall in zwei Sprints und im schlechtesten Fall in 4 Sprints fertig sein wird.
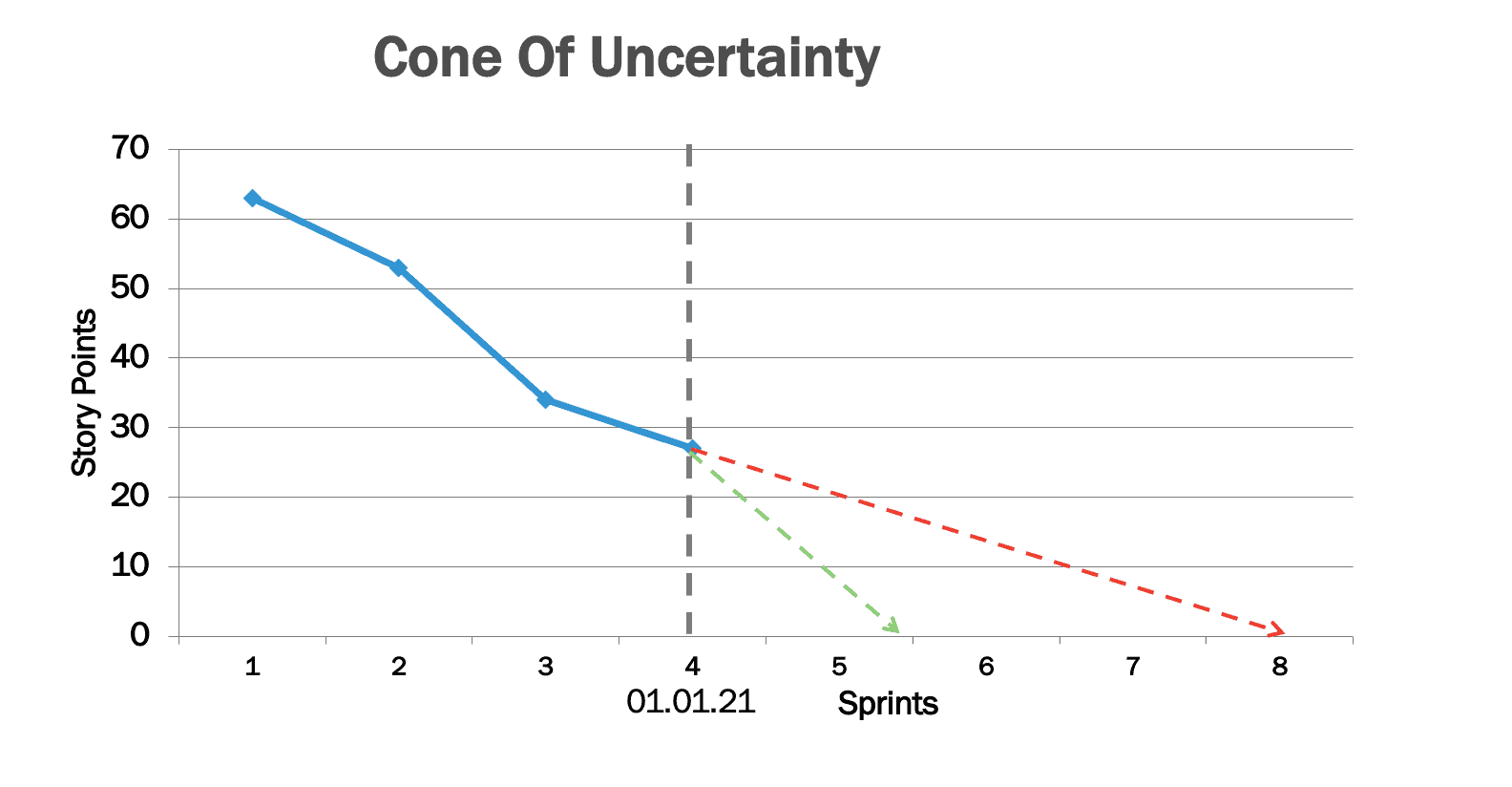
Im Gegensatz zu Vorhersagen, welche auf dem Durchschnitt basieren (blaue gestrichelte Linie), visualisiert der Kegel der Unsicherheiten mögliche Fertigstellungstermine, basierend auf bisher gesammelten Daten des Teams.
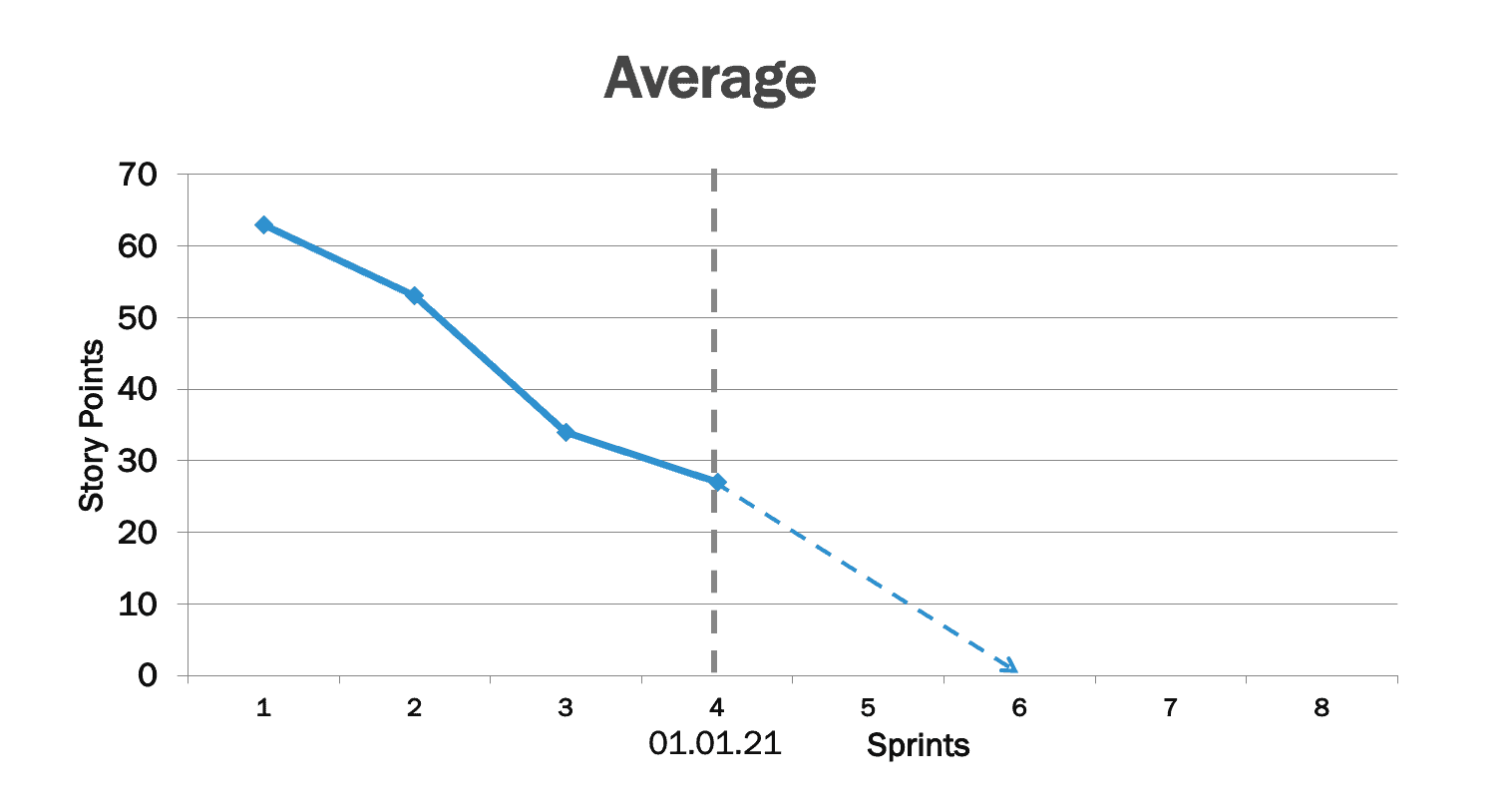
Eine Vorhersage mittels des Kegels der Unsicherheiten hilft Product Ownern die Frage, wann ein Feature fertig ist, durch die Angabe eines Bereichs möglicher Fertigstellungstermine zu beantworten. Dabei berücksichtigt die Antwort gleichzeitig die herrschende Unsicherheit in der Produktentwicklung, welcher das Team bis jetzt ausgesetzt war.
Antwort #2: Basierend auf Wahrscheinlichkeiten
Sollte die Visualisierung des Kegels der Unsicherheiten für die Beantwortung der Frage nicht detailliert genug sein, hat sich in den letzten Jahren für Product Owner bewährt, numerische Simulationen zu verwenden. Eine darauf basierende Prognose beschreibt eine Reihe von Eintrittswahrscheinlichkeiten, wann das Feature fertig sein könnte. Im Unterschied zum Kegel der Unsicherheiten beziehen Prognosen die Ungewissheit durch die Angabe von Wahrscheinlichkeit noch aussagekräftiger ein.
Wenn wir in unserem Beispiel das hervorragende Throughput-Forecaster-Tool von Troy Magennis und Adam Yuret auf Focused Objective heranziehen, dann erhalten wir die folgende Prognose:
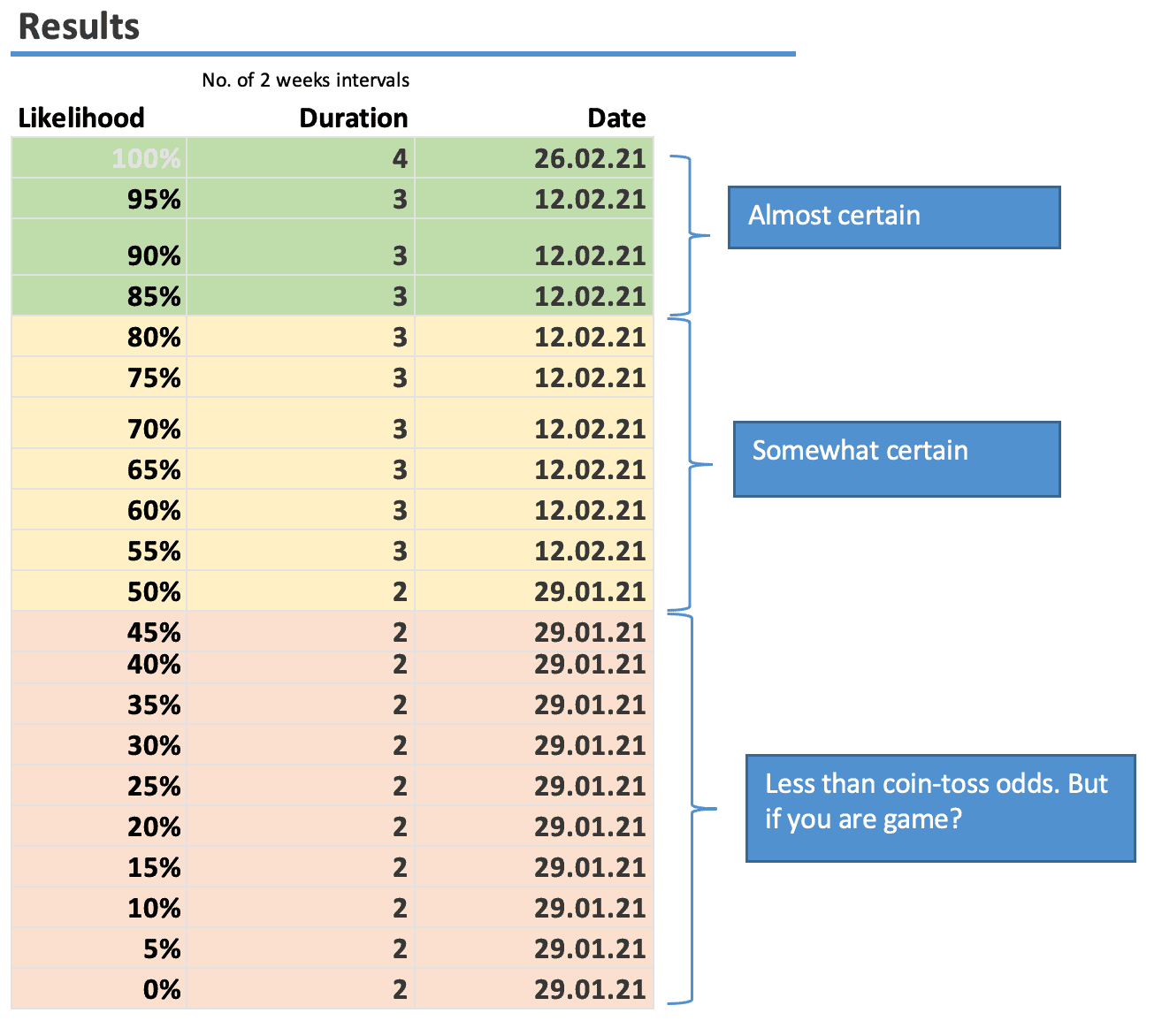
Die Frage, wann das Feature fertig ist, können wir detaillierter beantworten, indem wir sagen, dass wir mit großer Zuversicht denken, dass das Feature in den nächsten 4 Sprints fertiggestellt wird. Hierfür beträgt die Wahrscheinlichkeit bis zu 100 %. Nur mit Zuversicht können wir sagen, dass das Feature in den nächsten drei Sprints fertig wird. Dass das Feature in den nächsten zwei Sprints fertig wird, ist hingegen sehr unwahrscheinlich, da die Wahrscheinlichkeit dafür maximal 50 % beträgt.

Die Genauigkeit numerischer Simulationen kann erheblich verbessert werden, wenn wir noch weitere Daten, wie
- die Velocity der letzten sieben Sprints,
- die Häufigkeit, mit der Produkt-Backlog-Einträge zerteilt wurden, und
- das Verhältnis, wie viel die Teammitglieder in diesem Team arbeiten
gesammelt haben.
Warnung #2: Eine Prognose bleibt eine Prognose
Auch wenn man sich für die Beantwortung der Frage, wann das Feature fertig ist, nicht auf den Durchschnitt verlässt und stattdessen den Kegel der Unsicherheiten oder Wahrscheinlichkeitsverteilung heranzieht, sollte man eines niemals vergessen:
Alle Antworten sind nur Prognosen. Bei komplexer Arbeit ist nur eines gewiss: Was passieren wird, ist ungewiss.
Wie beantwortest du die Fragen, wann ein Feature fertig sein wird? Schreibe es gerne in die Kommentare.






Dem Ansatz, mit Unsicherheiten und Wahrscheinlichkeiten zu arbeiten, statt nur eine einzelne Zahl dazu zu nennen, wann ein Feature fertig sein wird, stimme ich vollkommen zu.
Der Aufhänger des Artikels mit der Wahrscheinlichkeit 1/32 ist so aber falsch. Die Wahrscheinlichkeit, dass das Feature aus 5 Items nach 2 Sprints (oder schneller) fertig wird, ist nicht 1/32, sondern eher 50%, wie ja auch die Tabelle in Antwort#2 zeigt.
Folgendes passt nicht: Damit das Ergebnis 1/32 herauskommt, wird zunächst angenommen*, dass jedes der 5 Items wie ein Münzwurf eine Chance von 50% hat, „pünktlich“ (also in der erwarteten Zeit oder schneller) fertig zu werden. Daraus folgt dann (unter der Annahme, dass die Pünktlichkeiten der Items sich nicht gegenseitig beeinflussen), dass es eine Chance von (1/2)^5 = 1/32 gibt, dass alle 5 Items für sich betrachtet pünktlich abgeschlossen wird. So weit so gut.
Jetzt kommt allerdings der Knackpunkt: Es kann auch passieren, dass ein oder mehrere Items nicht in der erwarteten Zeit fertig werden, das gesamte Feature aus 5 Items aber schon, weil andere Items dafür schneller fertig werden als erwartet. Die erwartete Zeit, die ein Item benötigt, wird ja aus dem Durchschnitt über alle bisherigen Items berechnet. Es gibt also auch immer mal wieder Items, die schneller fertig werden als erwartet.
Anders als bei einem Meeting, in dem alle Personen pünktlich erscheinen müssen, damit das Meeting pünktlich anfangen kann, müssen also nicht alle 5 Items notwendigerweise „pünktlich“ fertig werden, damit das gesamte Feature pünktlich fertig werden kann.
*Genau genommen müsste man hier noch zwischen der für das „Münzwurfmodell“ relevanten medianen Zeit (bei der 50% der Items darüber und 50% darunter liegen) und der Durchschnittszeit / erwarteten Zeit für ein Item unterscheiden. Ich denke es wird aber auch so klar, wo hier der Fehler liegt.
Danke Lennard,
dass du dir die Zeit genommen hast, meinen Artikel zu lesen und zu kommentieren. Du hast recht, das Argument mit dem Münzwurf vereinfacht die Situation vielleicht etwas zu sehr. Ich denke, ich ignoriere damit die bereits bekannte Velocity der letzten Sprints.
Ich habe versucht, dein Argument nachzuvollziehen, aber an einer Stelle bin ich etwas ins Stocken geraten. Du schreibst „Es kann auch passieren, dass ein oder mehrere Items nicht in der erwarteten Zeit fertig werden, das gesamte Feature aus 5 Items aber schon, weil andere Items dafür schneller fertig werden als erwartet.“ Nimmst du hier an, dass die Produkt-Backlog-Einträge einer nach dem anderen abgearbeitet werden?
Hallo Simon,
für mein Argument spielt es keine Rolle, ob die Product-Backlog-Einträge (ich nenne sie im Folgenden Items, weil das kürzer ist) einer nach dem anderen oder (teilweise) parallel abgearbeitet werden. Wichtig ist nur, dass wir für jedes Item die Zeit schätzen, die das Team in dieses Item stecken muss, bis es erledigt ist.
Nehmen wir mal das Beispiel von oben, in dem wir festgestellt haben, dass das Team pro Sprint bisher im Durchschnitt 13 Story Points abgearbeitet bekommen hat. Damit die Zahlen im Folgenden nicht so krumm werden, gehe ich jetzt mal davon aus, dass ein Sprint 13 Arbeitstage enthält. So können wir dann sagen, dass wir erwarten, dass das Team in ein Item mit 8 Story Points 8 Tage Arbeit stecken muss (ich meine hier 8 Tage Arbeit des gesamten Teams, nicht 8 Tage eines einzelnen Teammitglieds, sonst müssten wir noch mit der Anzahl der Teammitglieder multiplizieren). Ob diese 8 Tage dann tatsächlich 8 Arbeitstage am Stück sind, weil das ganze Team nur an diesem Item arbeitet, oder ob ein Teil des Teams parallel an anderen Items arbeitet, ist für diese Rechnung egal. Das Team hat eben pro Sprint 13 Arbeitstage zur Verfügung, die irgendwie auf die Items verteilt werden, die fertigzustellen sind. (Wenn man von einer realistischeren Zahl von 10 Arbeitstagen pro Sprint ausgehen würde, würden wir erwarten, dass (8*10)/13 Tage Arbeit in das Item mit 8 Story Points gesteckt werden müssen, bis es fertig ist, ich bleibe jetzt aber mal bei dem 13-Tage-Sprint).
Wir haben dann also folgende Items im Backlog für unser Feature, das fertig werden soll:
Item A: 8 Storypoints, erwarteter Aufwand 8 Arbeitstage
Item B: 5 Storypoints erwarteter Aufwand 5 Arbeitstage
Item C: 6 Storypoints, erwarteter Aufwand 6 Arbeitstage
Item D: 2 Storypoints, erwarteter Aufwand 2 Arbeitstage
Item E: 5 Storypoints, erwarteter Aufwand 5 Arbeitstage
Jetzt kann es ja passieren, dass nach zwei Sprint (also 26 Arbeitstagen) alle fünf Items erledigt sind, obwohl eines oder mehrere von ihnen mehr Aufwand benötigt haben als angenommen, weil andere Items weniger Aufwand benötigt haben als angenommen. Zum Beispiel so:
Item A: Erwarteter Aufwand 8 Arbeitstage, tatsächlicher Aufwand 9 Arbeitstage
Item B: Erwarteter Aufwand 5 Arbeitstage, tatsächlicher Aufwand 4 Arbeitstage
Item C: Erwarteter Aufwand 6 Arbeitstage, tatsächlicher Aufwand 5 Arbeitstage
Item D: Erwarteter Aufwand 2 Arbeitstage, tatsächlicher Aufwand 3 Arbeitstage
Item E: Erwarteter Aufwand 5 Arbeitstage, tatsächlicher Aufwand 5 Arbeitstage
In der Summe musste das Team hier 26 Arbeitstage in die fünf Items stecken, sie wurden also innerhalb von 2 Sprints fertig, obwohl Item A und Item D aufwändiger waren als erwartet; dafür waren hier Item B und Item C weniger aufwändig als erwartet, die Fehler bei der Aufwandsschätzung haben sich also genau ausgeglichen.
Jetzt kann man natürlich sagen, dass ich dieses Beispiel genau so konstruiert habe, dass es wieder passt. Aber mein Punkt ist auch nur, dass es durchaus vorkommen kann, dass das Feature aus den fünf Items pünktlich fertig ist, auch wenn einzelne Items länger bearbeitet wurden als angenommen. Nur weil Item A einen Tag länger gebraucht hat als erwartet, ist es immer noch möglich, dass das Feature aus allen fünf Items innerhalb von 2 Sprints, also 26 Arbeitstagen, fertiggestellt wird.
Reduziert auf das Münzwurfmodell hätten wir hier drei Items (B, C und E), die pünktlich fertiggestellt wurden und zwei Items (A und D), die nicht pünktlich fertiggestellt wurden. Diese Information ignoriert aber, wie viel Mehr- oder Wenigeraufwand bei den einzelnen Items tatsächlich angefallen ist, und dass diese Mehr- und Wenigeraufwände sich auch ausgleichen können. Deshalb ist die Wahrscheinlichkeit, dass jedes der 5 Items pünktlich fertig wird, deutlich kleiner als die Wahrscheinlichkeit, dass die 5 Items in der Summe pünktlich fertig werden.
Vielleicht noch ein Beispiel, um das Problem nochmal mit konkreten Wahrscheinlichkeiten zu verdeutlichen: Wenn man mit einem normalen Würfel würfelt, ist der Median und der Erwartungswert für das Ergebnis eines einzelnen Wurfs 3.5. In 50% der Fälle (1, 2, 3) kommt etwas kleineres als 3.5 heraus, in 50% der Fälle (4, 5, 6) etwas größeres.
Wenn man fünfmal würfelt, ist die Wahrscheinlichkeit, dass man ausschließlich Zahlen zwischen 1 und 3 würfelt (also ausschließlich Zahlen, die kleiner als 3.5 sind), (1/2)^5 = 1/32, also 3.125%.
Wenn man aber die Summe über die fünf Würfe bildet, ist die Wahrscheinlichkeit genau 50%, dass sie kleiner ist als 17.5 (17.5 = 5*3.5).
Selbst die Wahrscheinlichkeit, dass die Würfelsumme über fünf Würfe höchstens 15 (=5*3) ist, liegt bei etwa 30%, ist also deutlich größer als 3.125%. Denn auch wenn man mal eine 4, 5 oder 6 würfelt, kann das ja wieder dadurch ausgeglichen werden, dass man auch eine 1 oder 2 würfeln kann.
Die Berechnung dieser Wahrscheinlichkeiten ist nicht ganz so einfach, ich habe sie von hier: https://www.rechner.club/wahrscheinlichkeit/wuerfelsumme-tabelle
Übertragen auf das Team, das Items abarbeitet, entspräche in diesem Modell (sicherlich kein besonders gutes Modell) das Ergebnis eines einzelnen Würfelns dem tatsächlichen Aufwand für ein einzelnes Item und die Summe über fünf Würfe dem tatsächlichen Aufwand für ein Feature aus fünf Items.
Danke Lennard,
für deine ausführliche Erklärung. Nun habe ich es glaube ich verstanden. Daraus lerne ich zwei Dinge:
1. Das Münzwurfbeispiel vereinfacht die Dinge vielleicht dann doch etwas zu sehr. Ich hätte im Post lieber gleich die Zahlen vom Throughput-Forecaster-Tool von Troy Magennis und Adam Yuret verwenden sollen.
2. Bei der Verwendung von Velocity muss man sehr aufpassen. Wenn wir zum Verständnis von Velocity, die Arbeitstage eines Teams heranziehen, helfen uns Story Points nicht mehr wirklich. Dann können wir auch gleich Arbeitstagen verwenden. Besser ist es wohl mit Durchsatz und Cycletime die Frage, wann ein Feature fertig sein wird, zu beantworten.
Danke, dass du dir die Zeit genommen hast und diesen Beitrag kritisch hinterfragt hast, es hat mir sehr geholfen mein Verständnis zu diesem Thema zu schärfen.
Vielen Dank Simon für die schöne Darstellung, besonders der späteren Antworten, die man sonst nicht so häufig hört!
Mutig finde ich allerdings die Aussage, dass etwas, das in der Zukunft passiert, eine Wahrscheinlichkeit von 100% hat. Würdest du wirklich dein Leben darauf wetten, dass dieses Feature in 4 Sprints kommt?
Guter Punkt. Es sollte natürlich bis zu 100% heißen. Danke. Ich habe es verbessert.