Schneller Software entwickeln – nur wie? Teil 2: Schleifen
Im ersten Teil der Artikelserie haben wir uns angeschaut, wie die benötigte Zeit für Produkt- oder Software-Entwicklung dominiert wird von Warteschlangen.
Wir haben herausgefunden, dass im dort beschriebenen Setup eine Gesamt-Durchlaufzeit von mindestens 25 Tagen für unsere Änderung haben werden. Schneller liefern werden wir nur in Ausnahmefällen (wenn wir bestimmten Änderungen Vorfahrt einräumen, was aber wiederum zu Verzögerungen bei anderen Aufgaben führt. Mehr dazu gleich).
Nun fügen wir den zweiten systemische Kern-Parameter hinzu: Schleifen (Loops). Um Schleifen zu verstehen müssen wir uns kurz vergegenwärtigen, dass wir in jedem Entwicklungsprozess Überprüfungs-Schritte einrichten werden. Wir müssen ja irgendwie beurteilen können, ob die anstehende Änderung für uns gut oder schlecht ist. Schlechte Änderungen sollen kein Produktionsstadium erreichen? (Es ist höchst unwahrscheinlich, dass wir sagen: ach, das wollten wir jetzt nicht, aber egal!)
Was tun wir also, wenn wir in irgendeinem Schritt unseres Entwicklungsprozesses ein Problem feststellen: wir senden das Problem an eine frühere Stelle zurück, um Abhilfe zu schaffen:
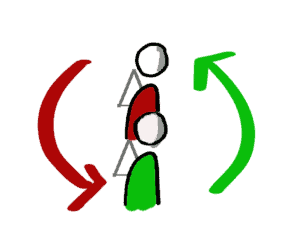
Zurückkehrende Arbeit ist eine Form von Schleife.
Wenn eine Code-Änderung noch einmal überarbeitet werden muss, dann versteht es sich von selbst, dass nach der Behebung des Problems wiederum alle Prozess-Schritte durchlaufen werden müssen. Das klingt auch gar nicht dramatisch, nur:
- Wenn wir Arbeit zu den Entwicklern zurückgeben, dann muss sie: warten, denn die Entwickler sind im Regelfall zu anderen Themen übergegangen,
- Natürlich könnten wir die so zurückgegebene Arbeit speziell “beschleunigen” (= an die Spitze der Warteschlangen stellen, siehe oben). Leider verzögert dies alle anderen Themen, die sich gerade in der Warteschlange befinden. Alternativ muss die Retoure eben warten, bis die aktuelle Arbeit abgeschlossen werden kann.
- Manchmal wird versucht, dieses Problem zu lindern, in dem wir einen separaten Priorisierungs-Schritt einführen. Ein Manager oder Product Owner priorisiert die zurückgegebene Arbeit gegenüber der anderen Arbeit des Teams. Wir erinnern uns: Wo immer wir eine Übergabe finden, gibt es eine Warteschlange. Dem Prozess wird so eine weitere Verzögerung hinzugefügt.
Irgendwann haben wir unseren Fehler behoben, sie kann erneut getestet werden. Wir stellen sie also zurück in die Testing-Warteschlange und fügen dadurch im Durchschnitt weitere 3 Tage hinzu, wie beim ersten Mal.
Tragisch wird es, dass wir auch dieses Mal nicht mit Sicherheit wissen können, ob unsere Arbeit jetzt problemlos durchläuft. Software-Entwicklung ist inhärent komplex, insbesondere bei unübersichtlichem oder unvertrautem Code. Unsere aktuellste Korrektur verursacht vielleicht ein Problem an einer anderen Stelle – und eine erneute Rückgabe.
Die dringend nötige Möglichkeit, schlechte Änderungen abzuwehren, sorgt also für weitere Zeitverzögerung im System.
In Summe – wie lange dauert es jetzt, eine Software zu ändern? Das hängt ab von der Zeit ab, die unsere Änderung in Warteschlange(n) verbringt, der Anzahl und Menge der anderen Änderungen, ihrer relativen Priorität – und: der Anzahl der Schleifen.
Jede Schleife führt dazu, dass die Arbeit alle existierenden Warteschlangen erneut durchlaufen muss. Und es kommt noch schlimmer: Jede Rückgabe von Arbeit verzögert geplante Arbeiten, sodass wir nicht mehr sicher sein können, ob selbst perfekt durchgeführte Änderungen in nur 25 Tagen das System durchlaufen können – denn das hängt eben vom Zustand aller anderen laufenden Arbeiten zu diesem Zeitpunkt ab.
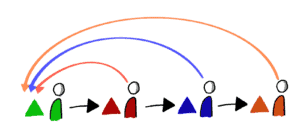
An diesem Punkt haben wir jeden Anflug von Vorhersehbarkeit verloren. Wir können keinerlei Aussagen mehr treffen, wann unsere Arbeit abgeschlossen sein wird.
Wer kennt sie nicht, die leicht frustrierten Aussagen a la “das kann doch nicht sein, dass so mein Änderungswunsch hier 30 Tage braucht”. Die valide Frage von Kunden und Stakeholdern „wann bekomme ich meine Änderung“ ist zum Politikum geworden.
Falls wir es vergessen haben: wir reden immer noch von “Änderungen, die im Durchschnitt knapp zwei Tage Netto-Aufwand benötigen”. Die aktive Arbeitszeit eines Entwicklers ist ziemlich vorhersehbar, auch das aktive Testen. Es ist die Wartezeit, die uns in der Berechnung schwerfällt.
Ohne ein besseres Verständnis der Auswirkungen des Entwicklungssystems erscheint es absurd, dass eine zweitägige Änderung möglicherweise monatelang nicht bereitgestellt wird.
Aber hier kommt der wirkliche Schocker: Die obige Beschreibung ist eine Vereinfachung der Realität. Wir sehen in der Realität langsamere und kompliziertere Arbeitssysteme.
Alle sind beschäftigt, aber nur wenige Dinge sind jemals fertig, wie wäre es also mit besseren Schätzungen?
An dieser Stelle ist die Gesamt-Organisation oft von der Un-Planbarkeit und Unvorhersehbarkeit von Ergebnissen frustriert und verlangt vielleicht von den Teams “präzisere Schätzungen”, die man dann an Kunden und Stakeholder weitergeben kann.
Das klingt auch ziemlich vernünftig, nur dass die Entwickler keinen Deut besser in der Lage sind, die “designte Unvorhersehbarkeit des Systems” zu überwinden, als alle anderen.
Am besten können wir mit dem Problem umgenen, in dem wir statistische Methoden verwenden:
Wie alt ist ein Work Item (Minimal, maximal, Durchschnitt), wenn es schließlich in Produktion geht? Wie groß ist die Standard-Abweichung? Nur: Können wir den Benutzern unter die Augen treten sagen, dass eine neue Idee, die heute in den Prozess eingeht, mit einer Wahrscheinlichkeit von 85 % in 157 Arbeitstagen (plus oder minus 20) in Produktion kommt?
Die Gesamt-Organisation wird mit einem Aufschrei auf diese Information reagieren (157 Tage oder mehr!!). Leider können wir aktuell nur sagen: „Ist halt so“. Denn: es ist eine unvermeidliche Konsequenz des eingerichteten Systems. Eines Systems von Richtlinien und Entscheidungen, von Menschen eingeführt und organisch durch eine Reihe verschachtelter Verzögerungen effektiv zu einer Release-Verhinderungsmaschine gewachsen.
Jedes System ist perfekt (wenn auch nicht absichtlich) darauf ausgelegt, genau die Ergebnisse zu erzielen, die es produziert. – W.E. Deming
Daraus folgt: wir müssen ein System einrichten, das nicht die gleichen unerwünschten Verhaltensweisen und Ergebnisse zeitigt.
Wenn Sie ähnliche Muster in Ihrer Organisation erkennen, was sollten Sie jetzt tun: zählen Sie die Schleifen, die Arbeit bei Ihnen durchlaufebn muss und messen Sie den Anteil der Wartezeit an der Durchlaufzeit. Oder nehmen Sie Kontakt zu uns auf.
Im 3. und letzten Teil der Artikelserie zeige ich auf, welche Praktiken und Verfahrensweisen sich für ein besseres System bewährt haben.
Stay tuned!
(Hinweis: Die Artikelserie borgt Gedanken von Tim Ottinger von Industrial Logic, Verwendung mit Genehmigung.)